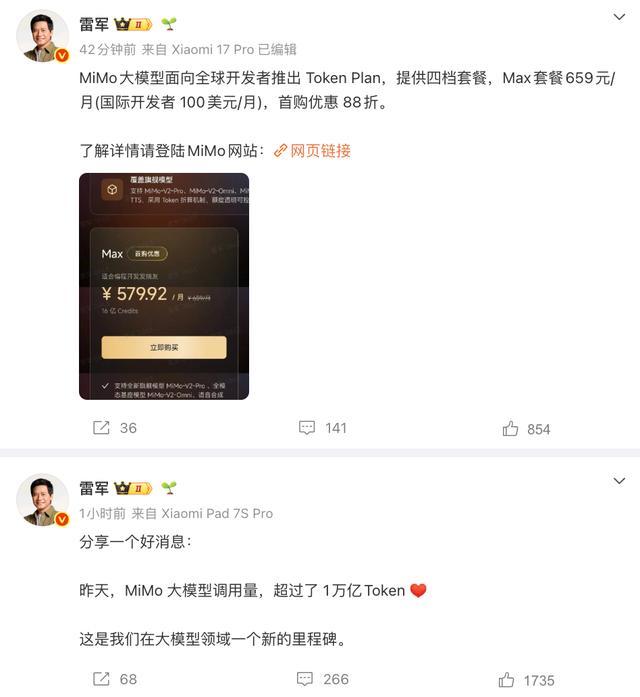
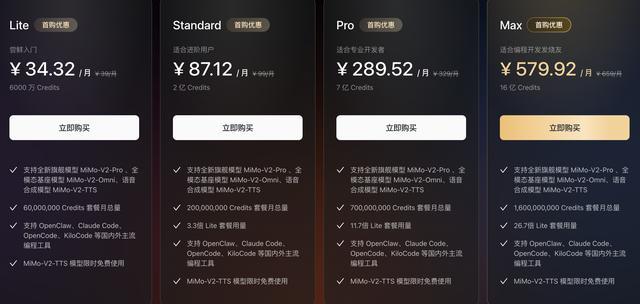
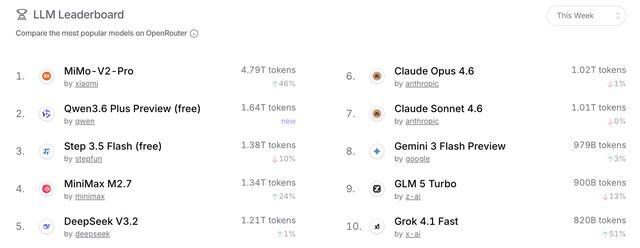
作者 Dale
编辑 董雨晴
“家庭确实是具身智能的圣杯。”2026年3月30日上午,深圳零一学院,自变量机器人联合创始人兼CTO王昊在包括凤凰网科技在内的一场访谈中给出了这个判断。彼时正值首届具身智能开发者大会(EAIDC 2026)举办期间,进入决赛的20支顶尖队伍在此集结,参赛者只有三天时间从零完成数据采集、模型训练到真机部署的全流程。
在几乎所有同行都在优先拿下工业场景订单的2026年,自变量选择了一条更具冒险性的道路。今年3月,自变量宣布与58同城合作,由58到家平台随机调度阿姨与机器人组成搭档,共同进行家政服务,已在深圳开启试点。家庭,这个标准化程度最低、环境最开放的场景,正在成为自变量心中“通往通用机器人”的关键战场。
01 一场把机器人拉回真实世界的比赛
本次EAIDC 2026的赛制设计颇有玄机,所有参赛队伍使用同一套硬件平台,三天之内从初次接触具身智能基座模型及真机调试的状态,完成从数据采集到真机部署的全流程。通常情况下,专业研究实验室完成类似搭建至少需要6个月。
在王昊的观察中,比赛开始的第一天下午就出现了显著分化。“第一天下午开营,到了晚上有的选手还在调试环境,有的选手已经有成绩了,这是很大的差别。”后来他发现,那些频繁评测、仔细观察数据和硬件的团队,相比不动手的选手更加突出。“整个具身是交互学习,让机器在测试、以及人对它的观察中找到问题,越有可能找到真正物理世界复杂性的解法。”
一位参赛选手后来回忆,他们在最初面对“将环套在柱子上”的任务时,成功率只有20%到30%,经过不断迭代才逐步提升至60%到70%。
比赛还设置了A榜和B榜——A榜环境可控,供选手快速验证模型能力;B榜则是完全黑盒,考验模型在光照、背景、操作对象和操作位置变化下的泛化能力。王昊说,这是他们做比赛的初衷:“想通过这次比赛真正让整个开源项目可以降低对开发者的使用门槛,建立一个相对比较通用和标准的接口”。
在长期依赖仿真评测的具身智能行业,仿真环境虽然可以加速迭代,却难以还原真实世界的复杂性,sim2real(指从模拟环境到现实世界的技术迁移方法)的差距始终存在。王昊坦言:“长期依赖仿真评测,不可避免会掩盖模型能力的真实边界”。而EAIDC这场“真机演武场”,试图将评测、训练和数据采集三者重新拉回到同一个真实世界中。
02 端到端的“新故事”?
自变量从一开始就选择了“大小脑统一的端到端大模型”路线。在技术架构上,团队正尝试将世界模型与VLA(视觉-语言-动作)模型融合在一个联合框架下。
王昊解释了这个路线的底层逻辑。“大语言模型这个训练基础还是要用,只是我们要把语言、动作拉到一个空间当中,而不是像以前那样让所有视觉都服务于语言。”语言描述的信息很宏观,而物理世界的交互发生在厘米级和秒级尺度上,两者之间存在巨大的信息鸿沟。“如果我们能采用原生多模态的方式,动作可以同时在宏观和微观上都有非常清晰的表现,它能把视觉从以前静态的观察变成让视觉理解运动。”
这与当前不少VLA模型的简化设计形成对比。有行业观察者指出,许多具身模型仍偏向简化,多数VLA模型仍依赖单帧图像输入。
王昊认为,端到端模型最大的挑战在于训练复杂度和规模要求。“如果没有具备这两个条件,你选择端到端不一定有选择垂类小模型或分层模型的效果好。端到端意味着必须要有规模效应,数据量、模型参数量要上去。”此外,具身智能的评测也比语言大模型更棘手,“语言大模型可以看loss曲线,对具身来说往往不是这样,loss不能反映你在真实世界的表现,因为真实世界是闭环的系统。”
自变量的另一个核心策略是坚持真实世界的真机数据采集。王昊说,所有交互式学习和强化学习,最重要的数据都来自真机,“这个数据采集不会停,还会继续做。”但他也透露,2026年会有一个大的变化——“越来越依赖于人的穿戴式或Ego-Centric的方式采集数据”。
数据闭环的构建是自变量的另一个关键命题。王昊说:“尽早用人机协作的方式,让闭环跑起来。首先用高质量数据、大规模训练构建一个基础模型,虽然不能解决所有任务,但应该把它放到真实环境中开始做。它有做不好的地方,人就接管它,帮它从错误中恢复,这样的数据也会作为非常宝贵的来源。”他描述的是一套评测、训练和数据采集在同一过程中完成的系统。
03 为什么是家庭?
事实上,业内人士普遍判断家庭场景成熟应用需要等待5到10年,多数厂商在商业化上更倾向于工业场景——环境可控、任务单一、ROI可核算。2026年初,一批估值百亿的机器人公司涌现,而在家庭服务这个方向上,目前尚无真正意义上的成熟玩家。
王昊给出了不同的解题思路:“家庭代表最开放的环境和最广泛的任务,解决了家庭任务,就代表模型可以实现完全泛化。只有一开始就直面最复杂的场景,才能提升模型的智能化水平。不管从什么时候开始,越早开始越好,这是最重要的。”
然而,进入家庭有几个关键难点。一是零样本泛化能力——模型必须通过推理探索成功路径,而非依靠预先训练。“进入家庭一开始没有多少机会训练模型,这时候需要激发模型的推理能力,让它在家庭场景中通过推理探索出成功的例子。”二是长程操作的精细度。“现在基模进入家庭,在很多任务上有完成的趋势或动作意图,比如可以在任何物体上有伸过去抓它的趋势,但精细度不够,导致复杂长程任务时错误累积就会失败。”
王昊介绍,解决长程精细度问题有两个关键。第一是激发模型的推理能力,“让语言结合视觉进行推理,语言、视觉、动作在同一个水平下形成思维链,让机器人自己规划和反思。”第二是在大规模真机情况下做强化学习,“保持在基模标准下达到更高标准的空间精度。”
王昊预估“普通清洁、收纳这类任务,可以在1到2年时间实现完全自主。但要在所有家庭任务中实现闭环,时间可能要再长一点。”
这与自变量CEO王潜的表述形成呼应。王潜曾在采访中提到,今年内就能看到机器人以正ROI的方式实现商业化落地。而家庭场景的推进节奏显然更慢,但也更长远。
回到当下具身智能赛道最关心的争议性话题,技术路线选择与商业化孰轻孰重?
“在具身这个事情上,为了商业而牺牲技术而取得的成绩天花板不会高,真正高的天花板是商业与技术协同,由技术逐步推动商业的发展。”王昊认为,自变量的主线是让基模不停向前迭代,“但有一点,不要在垂直场景做太多模型系统,为了落地而做很多工程上的弥补。比如发现机器人在视觉上有盲区,就搞一个小模型来检测。短期来看可以帮助加快落地,但长期来看对基模的提升是危害的。”
这种坚持对应着自变量在场景选择上的逻辑——选场景的第一个依据是看它能否反哺基模能力。“不是说你先把技术做到完全泛化,再去考虑场景。恰恰相反,场景给你迭代,迭代让基模更强,更强的基模再反哺商业,才能形成完整的闭环。”
他透露,做基础模型的投入一直很高,公司从成立第一天起就在数据、算力和基础设施上大规模投入。“一旦建立规模化效应,当你投入10倍资源取得领先的时候,资源聚集效应会越来越明显,你会以数量级的优势在速度上超越别人。越早开始越有优势,越晚开始就越难做成。”