
早在一月份,就有Deepseek V4会在26年春节发布的传闻,但春节期间并没有发布。
媒体(路透社)报道,DeepSeek V4并没有把旗舰模型提供给英伟达这样的美国芯片厂商做性能优化,打破了在重大模型更新之前进行性能优化的行业惯例。提前访问权限只提供给了华为这样的中国芯片厂商。中国的AI芯片肯定不如英伟达成熟,硬件方面的适配需要更长的时间。这也许是延迟发布的一个原因。
两个多月后,4月24日,deepseek终于发布了V4大模型。
Deepseek 公众号发文称,在Agentic Coding领域,据评测反馈使用体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式,但仍与 Opus 4.6 思考模式存在一定差距。
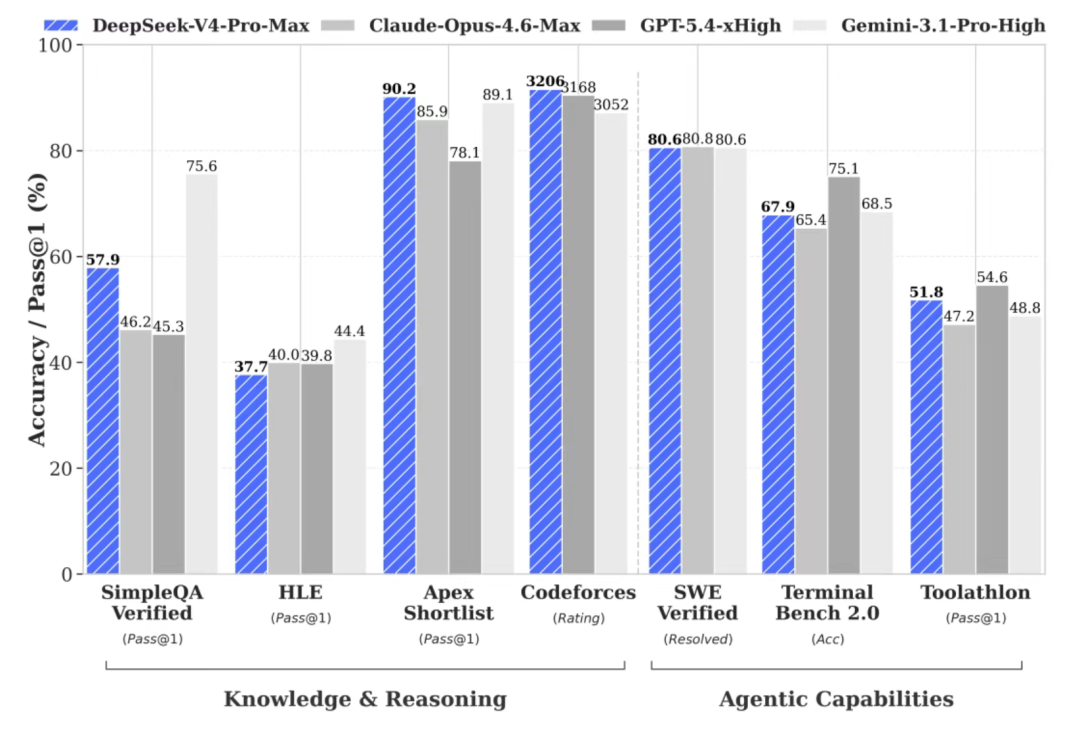
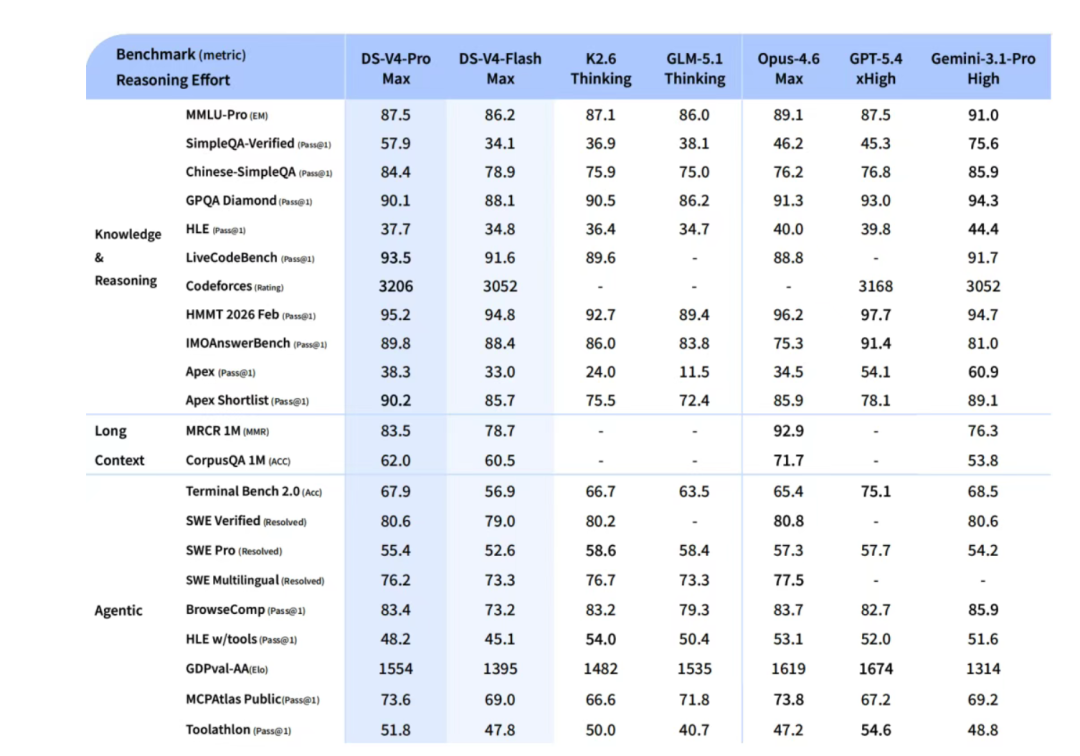
接近Opus 4.6已经是一个巨大的进步,最近几个月,anthropic的模型进步神速,从收入(ARR)和估值(场外交易)上已经超过了OpenAI。在文本和coding 领域已经是霸榜地位,LLM Arena排名前四位都是Claude Opus模型。
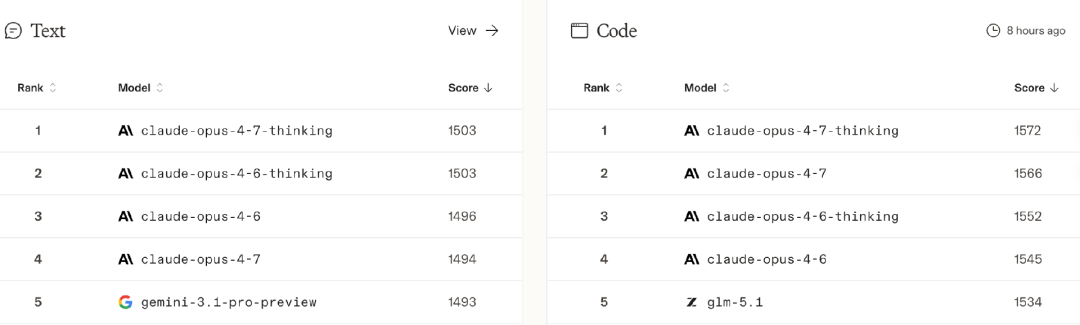
如果Deepseek V4在达到Opus 4.6的水平,意味着在文本方面和Code方面分数,都能进入全球前5名的行列。
斯坦福大学年度AI报告,每年都会更新一张图 - 中国最强的大模型和美国最强的大模型之间的分数差距。可以看到,上一次中美大模型最接近的时刻,就是2025年初Deepseek R1的发布。如果Deepseek V4真的达到了Opus 4.6的水平,意味着Deepseek再次缩短了中美大模型之间的差距。
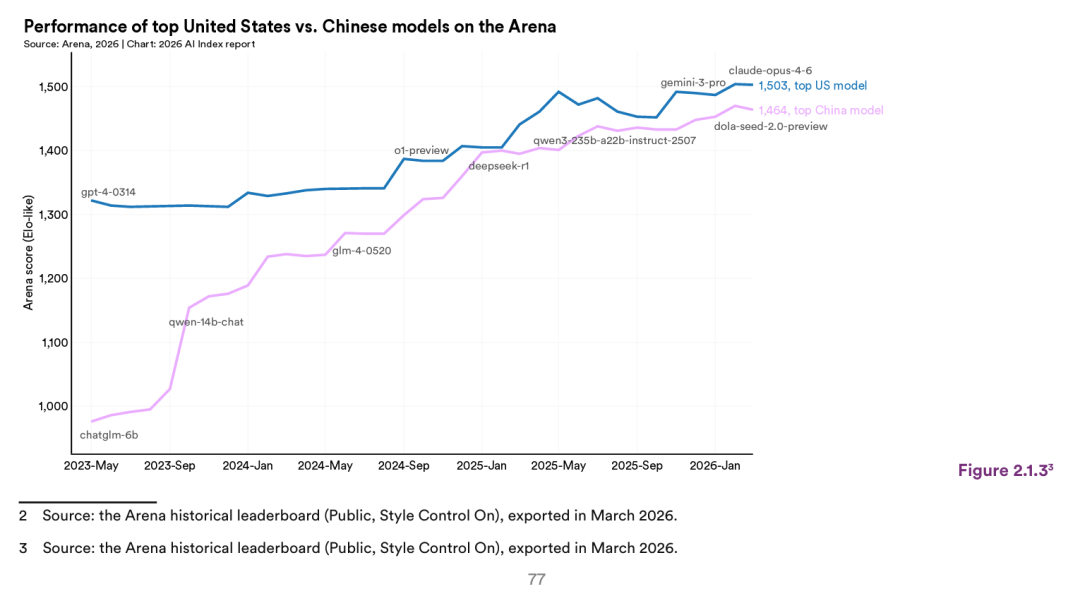
之前在一次会议中,千问团队前负责人林俊旸发言认为,美国AI厂商手里的算力比中国厂商整体大1-2个数量级。从算力的角度,美国是一群有钱人,中国是一群穷人。
美国在半导体领域卡中国的脖子,禁止高端AI芯片出口。中国的AI厂商在螺蛳壳里做道场,尽最大努力优化效率。中美AI领域的竞争,好比小米加步枪对飞机大炮。在如此不利的情况下,中国的AI厂商虽然没有实现超越,但还能紧追不舍,把中美之间的差距维持在六个月左右。
中国算力不足,优化效率带来的一个优势就是,中国的AI厂商能以更低的成本提供服务。美国顶级模型的Opus的价格是每百万Token 5 (输入)/ 25 (输出)美元。差一点的GPT 5.4 high/Gemini Pro 输出也要十几美元。而中国的模型价格是美国模型的五分之一。
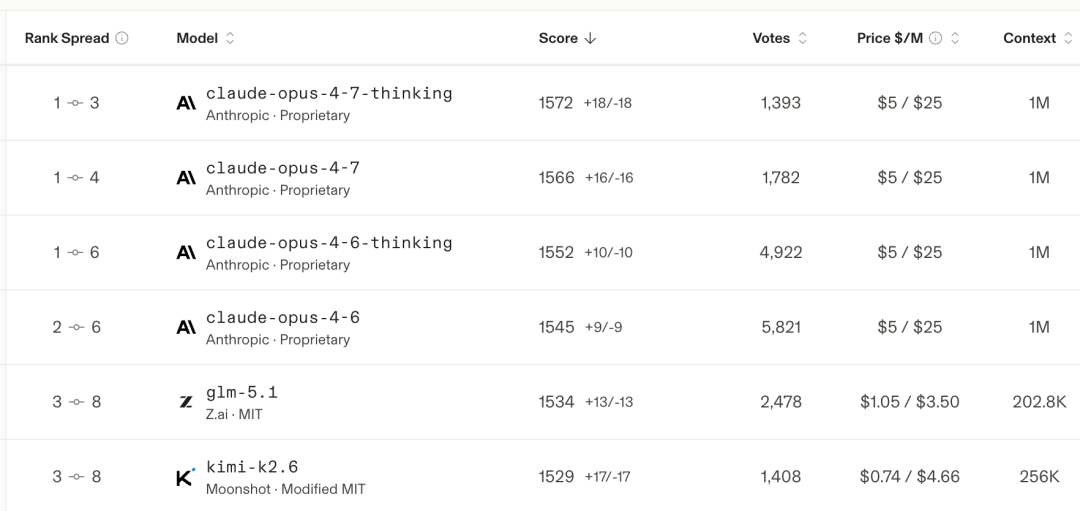
Deepseek这次公布的模式价格,和之前智谱的GLM 5.1差不太多,稍微贵一点,远远低于美国模型的价格。
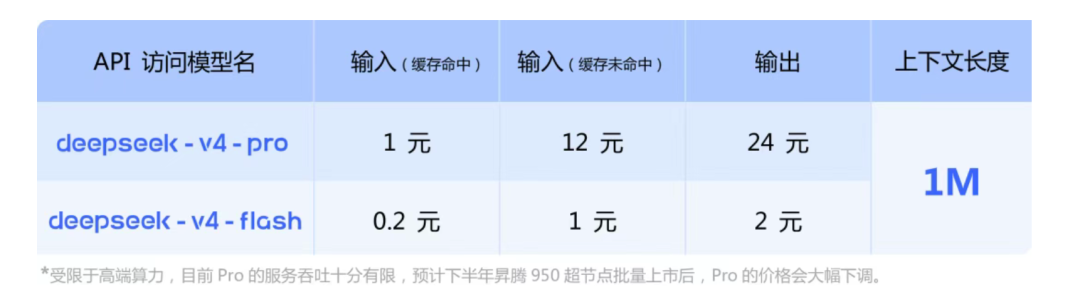
Deepseek 在报价表中还补充了一点,预计下半年昇腾950节点批量上市后,PRO的价格会大幅下调。
从Deepseek公布的文档看,V4的推理路径已经具备跨算力平台的适配能力,方案同时在 NVIDIA GPU 和华为 Ascend NPU 上完成验证。如果昇腾950上市后,能大幅降低PRO的价格,说明昇腾方案在成本上可能比NVIDIA方案更有优势。
和中国其他领域的赶超类似,大模型领域,中国厂商目前的杀手锏还是低成本。中国厂商能用几分之一的成本,提供有差距,但差距不大的产品。
Deepseek V4发布,肯定不如2025年那次发布轰动,但同样是一件了不起的成就。包括Deepseek在内的中国AI厂商,用十分之一的算力,五分之一的价格,维持着美国顶尖模型落后几个月的差距。
我上一篇文章中,认为中美两国目前的经济战,就是The Chokepoint Race。中国全力突破半导体芯片的卡脖子,美国全力突破稀土的卡脖子。谁先突破,在斗争中就拥有了主动权。
芯片设计这方面,中国没什么问题,海思当年就证明了能设计出不亚于高通的芯片。芯片卡脖子卡在芯片制造上。制造方面,如果有光刻机,中芯国际也能在短期内达到台积电的水平。今天,卡住中国脖子的就是ASML的光刻机。
美国卡中国的脖子,主要靠的是一家荷兰公司。美国AI大模型厂商真正的护城河,不是他们自己,而是ASML的光刻机。
如果有一天中国光刻机突破了,ASML、台积电、英伟达、OpenAI / Anthropic 这条半导体/AI 产业链的盈利水平和估值都将完全不同。
这一天何时到来?我不知道,也许五年、也许十年。但总有一天会到来。