
智东西
作者 | 云鹏
编辑 | 漠影
今天,AI算力军备竞赛如火如荼,从抢芯片到囤算力,GW(吉瓦)级数据中心一座接一座拔地而起,海外科技巨头更是动辄掀起数万亿元级别的AI基建大工程。
但钱真的“花在刀刃上”了吗?或者说,“囤”的算力真的有被充分利用吗?
根据国内RISC-V架构AI芯片领域头部玩家之一奕行智能的研究团队测算,各类AI加速器的实际利用率远低于理论峰值。
问题不在于芯片不够强,而在于现有的软件调度方式,无法在运行时灵活地“喂饱”硬件。有人将卖算力比作AI“卖铲子”,但同样一把铲子,用什么力度、角度去挖,在老师傅和菜鸟的手里,效率或有天壤之别。
我们看到,AI算力领域的下一波红利,在于购买更高利用率的芯片,把每一分算力,真正用满、用好。
在此背景下,近期智东西与奕行智能进行了深入交流,了解到其最新突破性研究正直指这一AI芯片行业痛点,其内部已研发实现基于Tile级虚拟指令集实现AI加速器的动态调度(TISA)。
简单来说,TISA构建了一套“让芯片在运行时自己做决策”的动态调度架构——在编译器和硬件之间建立一种新的调度语义契约,使芯片能基于实时状态智能分配任务。
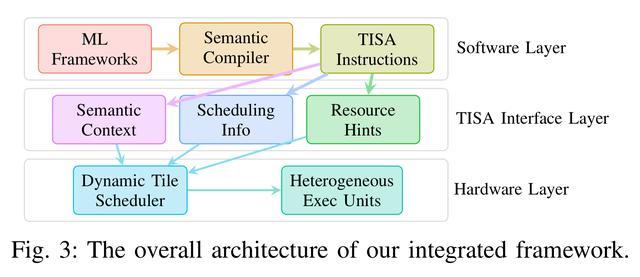
TISA整体架构示意图
值得一提的是,TISA 动态调度架构论文《Dynamic Scheduling for AI Accelerators via TISA》正式入选 ISCA 2026,这也是国内AI芯片公司在ISCA上的重要突破。
要知道,ISCA如同计算机体系结构界的Nature,是该领域历史最久、最具影响力的会议,这代表奕行智能的核心技术路线已经获得国际同行的正式认可。
可以说,让有AI算力需求的玩家们“花小钱办大事”,在AI时代更好地把握机遇方向上,奕行智能实现了一次重要突破,给产业破局提供了一种新的思路。
一、芯片买了钱花了,为什么效率提升跟不上?解密TISA三项核心突破
当前,各类前沿AI芯片单卡算力动辄达到几PFLOPS(每秒千万亿次浮点运算)甚至几十PFLOPS,峰值算力大幅提升,但相比算力的大幅提升,芯片算力利用率的提升却远未达到理论峰值。
从AI芯片内部结构来看,矩阵计算单元、向量计算单元,以及数据搬运单元协同运行,三者各司其职,同时持续满负荷运转才能实现最高效率。但当前AI芯片中主流采用的“编译时静态调度”模式,会在在程序运行前就把所有任务的执行顺序一次性排定。
这就像工厂厂长提前排好了生产计划,却不考虑工人临时请假、设备临时故障、原料临时缺货等情况(对应芯片运行时的带宽争用、温控降频等随机扰动),很容易造成流水线“空转干等”。
即便部分现代GPU在线程束(warp)调度等底层机制上引入动态调度,但这些机制仅在极细的指令粒度上运作,仅能解决CUDA Core内部的指令调度问题,无法协调数据搬运单元TMA、Tensor Core与CUDA Core三者的并发执行,仍存在局限性。
相比之下,TISA架构是如何突破这一瓶颈的?整体来看,主要是三项关键技术创新。
首先是语义保留编译器,其作为“翻译官”,可以做到不丢失“背景信息”。传统编译器把AI模型翻译成芯片指令,往往会丢弃算子类型、依赖关系等关键语义信息,就像转述菜谱是只说操作步骤,却不说每一步需要用什么材料、什么厨具、目的是什么。而奕行智能的编译器在翻译每一步时都会刻意保留这些“上下文”,让芯片执行的每一个计算任务都有完整说明,这是后续智能调度的信息基础。
第二个重要创新是给每一个计算任务都附带一张标准化“任务说明卡”,实现Tile级指令集TISA,说明卡会注明计算类型、所需硬件、依赖数据结果等信息,借此,芯片在运行时不再需要“猜测”就能精准判断和规划任务的并行和等待。
形象地来看,在AI计算过程中,AI编译器会将大算子切分为可独立调度、并行执行的小块,抽象成为一个个“Tile(数据块)”,就像把一座积木城堡拆解为一个个积木块,在保证计算完整的同时,能显著提升调度灵活性与硬件利用率。
这已经成为目前行业的共识,2025年Tile编程范式迎来爆发:从英伟达发布CUDA 13.1与cuTile工具链到北大开源TileLang获得“国产Triton时刻”的赞誉,再到DeepSeek更宣布新模型算子优先用TileLang做精度基线。可以说,让Tile抽象成为行业共识,既能适配AI模型特性,又能充分挖掘芯片并行潜力。
第三是构建芯片的“实时大脑”,奕行智能对其命名为冲突感知运行时调度器,这也是整套系统的核心。调度器持续监控芯片上所有计算单元的状态,一旦发现某个单元空闲,会立刻从待执行任务中找出满足条件的任务推送过去,整个决策过程极为迅速,从判断到下发仅需几纳秒,不会给芯片带来额外负担,但可以大幅降低各单元“空等”时间。
相比在软件层通过算法进行运行时调度有微秒级延迟,奕行智能的动态调度在硬件层实现,速度可以快100到1000倍,每一个调度决策可以保证在纳秒级内完成,减少延迟带来的损失,可以说,TISA也一定程度上代表了其软硬协同能力。
从实际案例测试来看,在目前大模型推理中公认最先进的注意力机制实现FlashAttention-3中,相比CUDA版,TISA版本代码量减30%,同步调用减少50%,性能达到手调基线的95%以上,并且由编译器自动生成的,无需任何手工优化。

CUDA版代码(左)与TISA版代码(右)对比
值得一提的是,同一套TISA指令流不仅可以在奕行智能自研芯片EPOCH上运行,也可以适用于其他第三方硬件平台。
总体来看,TISA首次在AI芯片领域实现了Tile粒度的动态调度,填补了行业空白,首次定义了Tile级ISA作为软硬件间的调度语义接口。
对于行业来说,奕行智能提供了一条摆脱“算力依赖”,不再一味追求大,而是更高效地充分利用好既有硬件的技术路径,这对云端大模型推理和端侧AI部署等计算资源受限、成本控制敏感等场景均有直接价值。
二、深耕类TPU架构,兼顾AI计算通用和专用,硬件、软件、生态一个不能少
TISA架构实现突破的背后,是奕行智能在AI芯片领域长期深耕和深厚技术积累的一次阶段性成果展示。在交流中我们也了解到,奕行智能对AI算力产业发展有深入思考和关键判断,TISA技术突破正是其核心战略方向上的一次技术落地。
从产品技术布局上来看,在芯片硬件层面,奕行智能研发的国内业界首款RISC-V AI大算力芯片EPOCH已经在今年年初就实现了大规模量产出货,这也是业内率先采用RISC-V+RVV(RISC-V向量扩展)指令集架构、用于数据中心领域的AI算力芯片,填补了国内RISC-V架构在高性能AI计算领域的空白。

EVAS解决方案亮点
实际上,近期RISC-V架构在数据中心领域的应用已经成为行业重要趋势方向,包括英伟达重金投资RISC-V龙头企业SiFive以推动其数据中心业务与RISC-V生态系统的融合、Meta面向数据中心的AI芯片MTIA 300也利用了RISC-V向量核心、谷歌将RISC-V作为TPU芯片的底层指令集架构,与此同时,高通、Tenstorrent等相关领域全球科技巨头也在持续加大对“RISC-V+AI”的投入。
奕行智能可以说很早就看清并认定了这一方向,在其团队看来,RISC-V是当前最适合构建AI芯片的指令集架构:开放的图灵完备指令天然支持复杂控制流,可以补上ASIC/NPU的灵活性短板;RVV向量则天然契合AI张量计算,掩码操作原生支持稀疏矩阵;允许在标准之上扩展专用指令的定制化潜力,则让AI芯片可以更好地兼顾通用性与专用性。
在当前全球大国博弈日益激烈的背景下,相较于需授权的Arm和x86架构,RISC-V作为开源开放的指令集架构,天然具有中立性,在打破垄断、构建开放生态、构建自主可控的AI算力底座方面,有着不容忽视的战略意义。
在RISC-V的基础上,奕行智能在芯片架构设计方面有别于传统通用GPU,类谷歌TPU架构专门针对AI计算场景进行了原生优化,可以实现更高能效比,进一步提升AI训练与推理效率,降低算力部署成本。
其自研的E Link互联技术,既可作为AI计算模组内部的芯片间高速互联方式,同时还支持Scale Up与Scale Out融合组网,集合通信库加速,可以满足多种互联拓扑下对大带宽、低延迟的智算互联需求,支持前沿的在网计算。
可以说,这是国产自主高速互联的重要突破。
奕行智能的芯片产品已经面向国产主流大模型进行了深度适配优化,实测性能可以达到国内领先、对标国际一流的水准。在实测中,相比国际竞品,奕行智能芯片在模型推理速度显著提升:RestNet50提升52%,BERT-Base提升31%,GPT-J-6B提升25%,LLAMA2-13B提升43%,提升幅度明显。
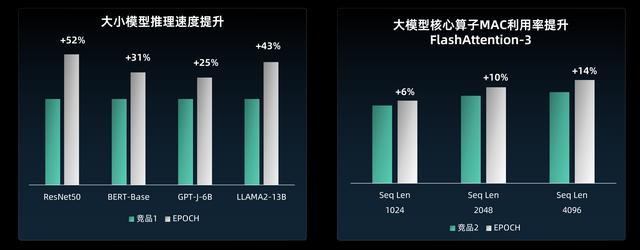
EPOCH与竞品芯片性能对比
实际上,类谷歌TPU的专用AI加速芯片通常都会在性能和能效比上有着比通用GPU更大的优势,但其主要挑战来自于生态适配成本,这也是行业努力的方向。
在降低生态适配成本、吸引开发者高效编程方面,基于Tile的编程模式本就能提供更友好的编程接口,提升算子开发效率,而此次入选顶会的独创Tile级动态调度架构,由Tile级虚拟指令集、智能编译器和硬件调度器组成,原生适配Tile生态范式,能实时适配硬件行为,充分挖掘芯片潜力,在编程方面也更为干净简洁。
Tile级动态调度架构的自动管理指令间依赖、指令顺序流水和内存切分,都可以显著提高编程易用性。
生态层面,奕行智能正积极与vLLM、Triton、gitee等国内外开源社区互动,与Triton国际社区合作,把Triton编译导流到RISC-V DSA后端,并将开源其虚拟指令集,合力打造针对RISC-V DSA的CUDA生态,对于RISC-V DSA整个产业的发展具有重要的战略意义。
值得一提的是,奕行智能还计划举办RISC-V AI 应用大赛,面向高校及科研院所开放合作,包括资源支持、技术培训交流等,进一步加速RISC-V产学研生态的发展和成熟。
三、最新旗舰AI芯片已大规模量产,拿下行业头部客户
此次奕行智能在TISA技术方面的突破可以快速落地到自家芯片以及各类主流算力芯片中,并非只是停留在实验室中的技术。实际上,在产业落地和商业化方面,奕行智能已经取得了长足进展。
奕行智能已经发布了多款AI芯片产品,据称其最新一代EPOCH在行业头部客户中持续取得商业突破,可以说是真正走到产业中去了。

当然,芯片赛道归根结底是“技术为王”,扎实的技术研发和产线体系的建立是奕行智能长期在坚持推进的,其核心团队来自业界顶尖系统与芯片公司,目前布局北京、上海、深圳、杭州、南京、广州等地。
从AI内核架构、编译器、ESL 建模,到芯片前后端设计、封测与量产的全链条自研能力,奕行智能均有布局。简单来说,他们有着全流程端到端交付能力和全链路商业化闭环能力。
作为国内唯一实现RISC-V云端AI算力芯片大规模量产的公司,奕行智能无疑已经成为AI时代RISC-V阵营在AI芯片赛道的核心扛旗手。
结语:从通用算力竞赛到能效比对决,AI芯片设计转向“运行时智能”
在交流中,奕行智能相关负责人提到,TISA架构突破带来的并不是一个简单的性能数字提升,而是AI芯片系统设计思路的一次重要转变:从“静态确定性”向“运行时智能”,编译器可以描述意图,进而让硬件实现实时决策。
当然,这背后离不开多项关键技术的创新以及完善软件工具和生态的支撑,在追寻更高能效比、更极致成本的今天,奕行智能着实给行业提供了一种新思路。
面向未来,行业变革仍在继续,成本的重压有增无减,AI算力产业已经从 “通用算力竞赛”进入了“能效比对决”时代,以TPU为代表的专用领域AI计算架构,以突出的能效比取得了市场成功,而奕行智能是其中跑的最快的一批。
在算力版图逐渐重塑、国内AI芯片竞争激烈之下,奕行智能已经成为强有力的行业挑战者和行业赋能者。