“我会建议所有LLM公司,在搞清楚‘coding plan怎么定价不亏钱’之前,不要盲目打价格战。”近日,小米集团MiMo负责人罗福莉在X平台发文,谈及针对眼下的Token定价问题发表看法。
让罗福莉下场发声的由头很简单:Anthropic在近期调整了产品策略,不再允许用Claude订阅运行OpenClaw。
本月4日起,Claude的Pro和Max订阅不再覆盖OpenClaw等第三方框架,用户如果还要继续使用这些智能体,只能改为通过API按量付费或购买额外使用额度。
Claude官方解释称:这类调用对系统造成了“远超预期的压力”。
而几乎在同一时间,MiMo也推出了自家的Token Plan。
“Claude Code的订阅机制在计算资源分配上设计得非常漂亮。但我认为它并不赚钱甚至可能亏损,除非API利润率高出10到20倍。”在文中,罗福莉这样分析道。
除了呼吁不打价格战,罗福莉的另一个核心观点是:长期来看,Agent时代的模型正在迎接一个“被迫进化”的过程,优化上下文管理、复用已有计算结果、减少无效token消耗是接下来的迭代方向。
在她看来,Anthropic的这一步,正在推动整个生态向这个方向:让高效的Agent和高效的模型协同进化。
不过,面对Anthropic这一策略调整,也有人选择了不买账。
OpenClaw作者Peter Steinberger在X上直接开喷,他表示,曾尝试与Anthropic沟通,但最终只争取到一周的缓冲时间。
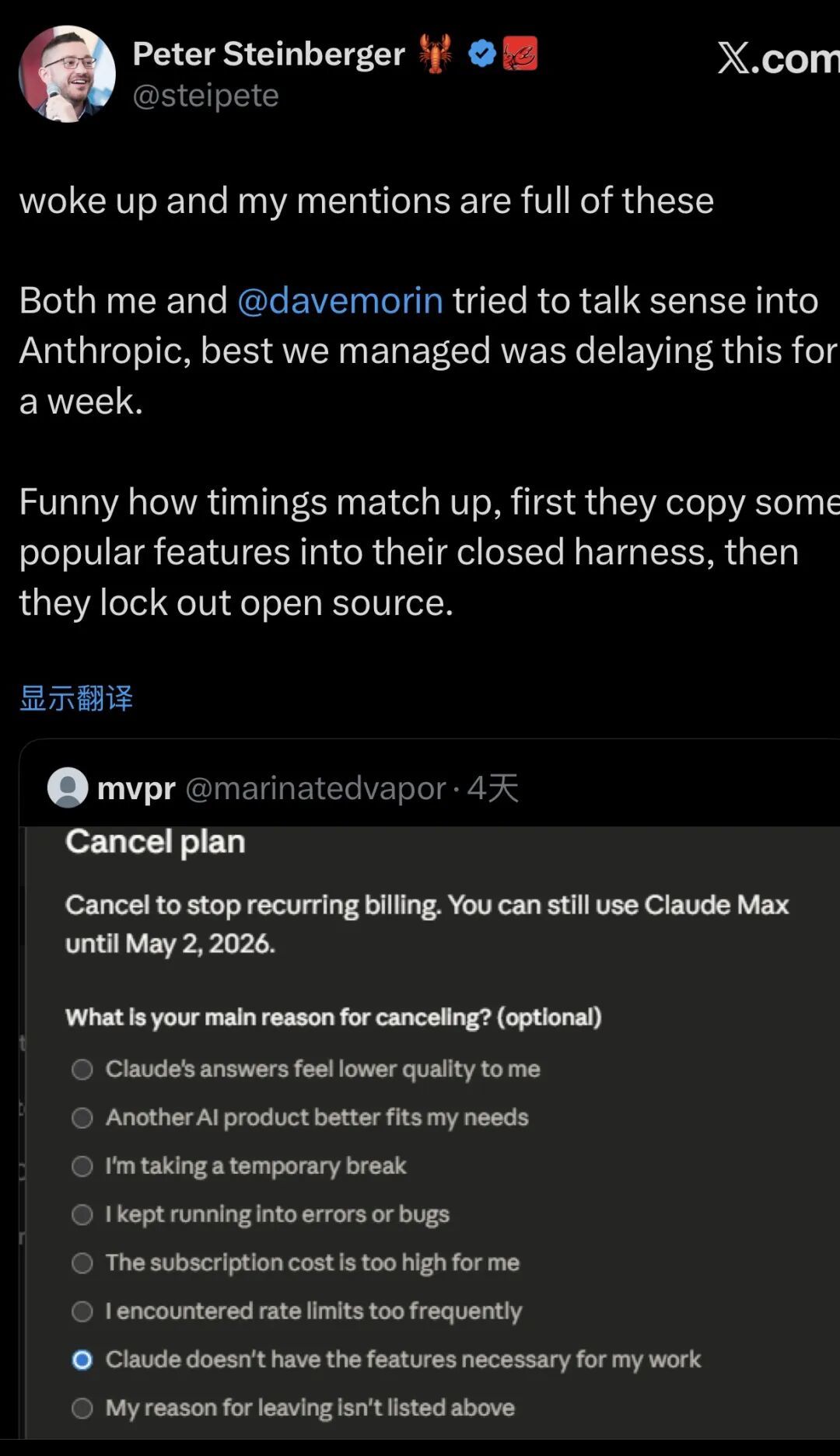
OpenClaw的广大用户群体无疑是这一轮调整的最大受害者,很多用户订阅Claude,本来就是为了运行OpenClaw,而现在,这条路径被直接切断。
当原本被认为“高昂价格”的200美元的订阅,突然间能跑出几千美元的算力消耗,无疑是对厂商定价策略的一次考验。
另一方面,这并非是一句简单的“Token调用变多了”就能解释的现象。Agent正在重塑Token的调用逻辑,而背后这笔账,算起来还真有点复杂。
01
600倍浮动下,模型该怎么定价
如果要用一个词来解释这场争议的核心,那就是——波动,不可预测的波动。
南洋理工大学等团队在近期发布的研究《Beyond Max Tokens》显示,在多轮工具调用的智能体场景中,同一个任务的计算消耗,可能出现最高658倍的差异。
一条看起来类似的任务,有的几千个计算单元就结束,有的则被拉到数万甚至更高。这意味着,模型的成本不只是变得更高,而是不可预测。
“我仔细观察过OpenClaw的上下文管理——做得不怎么样。”

解构罗福莉在X上的发言,你能发现和南洋理工这份研究的契合之处。罗福莉发现,在OpenClaw的一个用户请求里,往往会发起多轮低价值的工具调用,带来了巨大的模型调用量的浪费。
“真实成本很可能是订阅价格的几十倍。这不是差距——这是一个‘深坑’。”
罗福莉所说“深坑”,问题出在OpenClaw这类智能体的运行方式:一个任务往往需要多轮尝试和回退,很多计算并不会直接产生结果,但依然消耗资源。
但这个消耗资源的具体量级很难测算,这也是Claude选择封禁掉订阅接入Agent的渠道,而不是选择新设立一个“合理”定价的订阅套餐。
总而言之,随着Agent生态加速演变,Token用量的“合理”范围,压根无法准确预估。
“我们一直在努力满足不断增长的Claude需求,但我们的订阅服务并非为这些第三方工具的使用模式而设计的。”谈及这一次业务调整,Claude Code负责人Boris Cherny此前在X上这样写道。
他表示:“Token是一种我们谨慎管理的资源,我们将优先考虑使用我们产品和API的客户。”
对于这一调整带来的影响,有业内分析称之为“自助餐已经结束了”。OpenClaw开启了Agent的大航海时代,但也推翻了此前的模型定价门槛。一个OpenClaw代理运行一天,就可能消耗1000到5000美元的API成本。
“Anthropic正在承担每个通过第三方接口用户所产生的这部分差价,”增长营销专家Aakash Gupta在X上写道。“这就是一家公司眼睁睁看着利润实时蒸发的速度。”
成本完全失控,这是Anthropic不得不立刻做出反应的原因。
在Chatbot形态里,订阅制之所以能延续,是因为可以根据历史数据,统计出一个代表大部分用户的用量均值:轻度用户覆盖重度用户,整体成本可以被摊平。
但在Agent场景中,这种结构被打破。重度使用不再是个例,而是由产品形态本身决定的结果。只要模型开始“执行任务”,就必然会出现长链路调用、上下文膨胀和重复尝试。
类似的变化,其实已经在其他产品中出现。此前当Cursor在调整定价时,就从“按请求次数计费”转向“按实际Token成本折算的额度”,原因同样是长链路任务带来的成本差异,已经无法用固定配额衡量。
不过,用Token作为唯一定价、实算实销的方式虽然看起来很科学,但是也带来了新的问题,Agent链路下Token用量不确定性依然存在,如果完全用实际Token用量核算,相当于把这种不确定性转嫁给了用户。
因此,当Anthropic发表声明后,用户不买账的声音也此起彼伏。
X上有许多用户表示,切换到API计费跑OpenClaw成本会严重攀升,使得他们不得不考虑其他途径。
而已经被OpenAI“收编”的OpenClaw创始人Steinberger,在X上“开喷”也带了一丝叫板的意味。
有外媒分析,OpenAI似乎正在将自己定位为一个更“易于上手”的替代方案,并可能利用这一契机,从不满的Claude高级用户那里获取客户。
知名媒体Axios此前在报道中披露,曾有一位行业资深人士表示,“Anthropic强调训练和运行模型的效率,而OpenAI的心态是,CEO奥特曼总能筹集到更多资金来支持计算规模的扩展。”
这场争论的结局尚未可知,但毫无疑问的是,在2026年的AI领域,第三方自动化获得补贴、无限计算能力的时代已经结束。
不管采用哪种计费逻辑,更谨慎、更细化的Token收费模式已在路上。
02
配额不是唯一出路,但已是眼下最优解
进一步讨论定价问题前,有必要先解释下目前模型产品的主流计费模式。
目前主流模型厂商大致形成“三层计费结构”。第一层是订阅制,面向个人用户,如ChatGPT Plus、Claude Pro、Gemini Advanced,按月收费,提供更强模型与更高调用上限,但通常伴随速率与用量限制。
第二层是API按量计费,以OpenAI、Anthropic、Google以及国内火山引擎、阿里云、智谱等公司,按token或等价计算量收费,是开发者与企业的核心结算方式。
在此之上,各家又推出Coding Plan/Token Plan等套餐,作为订阅与按量之间的过渡形态:用户按月付费获得一定额度与优先权,但超额仍需按量付费,并伴随公平使用与限流机制。
在Agent场景中,这一分层尤为关键,自动化调用大都只支持API按量计费,订阅与套餐难以覆盖高强度、多轮调用的算力消耗。而大部分“订阅模式”只针对一般用户的Chatbot和内嵌Agent功能。
随着Anthropic针对Openclaw切换计费方式,其他厂商也相继做出反应,是更直接的——涨价。
过去几周时间里,一轮集中调价出现在国内AI云厂商中。
腾讯云此前宣布,自上月13日起结束部分模型的免费公测,并转为正式收费,同时对混元系列模型进行大幅调价,部分价格涨幅超过400%。
随后,阿里和百度方面也发布公告,本月月中开始上调AI算力和存储价格,整体涨幅在5%—30%区间。
而在几天前智谱的财报电话会议上,CEO张鹏披露,2026年一季度接口调用价格提升了83%,但调用量仍然增长400%。
接连几家AI云厂商涨价,说明了一件事:模型需求的增长来得太快,甚至厂商的基建层都倍感压力。
这一点在罗福莉的发文中也有体现:“更宏观地看:全球的算力供给,跟不上agent带来的token需求增长。”真正的出路,不是更便宜的token,而是模型和Agent的‘协同进化’。”
只是,在更高效的模型+Agent架构面世之前,涨价或者限制订阅,并不能解决这套计费逻辑中的核心矛盾。
从用户视角看,购买的是“任务完成”;但从模型厂商的视角,计量的是“计算过程”。
这两者之间,目前存在着明显的错位。走订阅,厂商要承担Token调用不稳定的风险;走API,这个风险又来到了用户身上。
这也是为什么“订阅+配额+API”的组合,同时出现在了各大厂商的落地方案中。
在Harness/Coding场景下,各类plan本质上是一种用户与模型厂商之间的相互妥协:厂商通过Coding/Token Plan套餐锁定一部分额度,换取用户侧的价格确定性,同时用限流和规则控制风险。
但在OpenClaw这类更不受控的agent场景中,调用强度和路径都难以约束,这种“妥协”很难成立,厂商们更多选择 API按量计费。
订阅负责轻量使用,配额限制极端消耗,超额部分按量计费。本质上,这是一种对不确定性的缓冲机制。
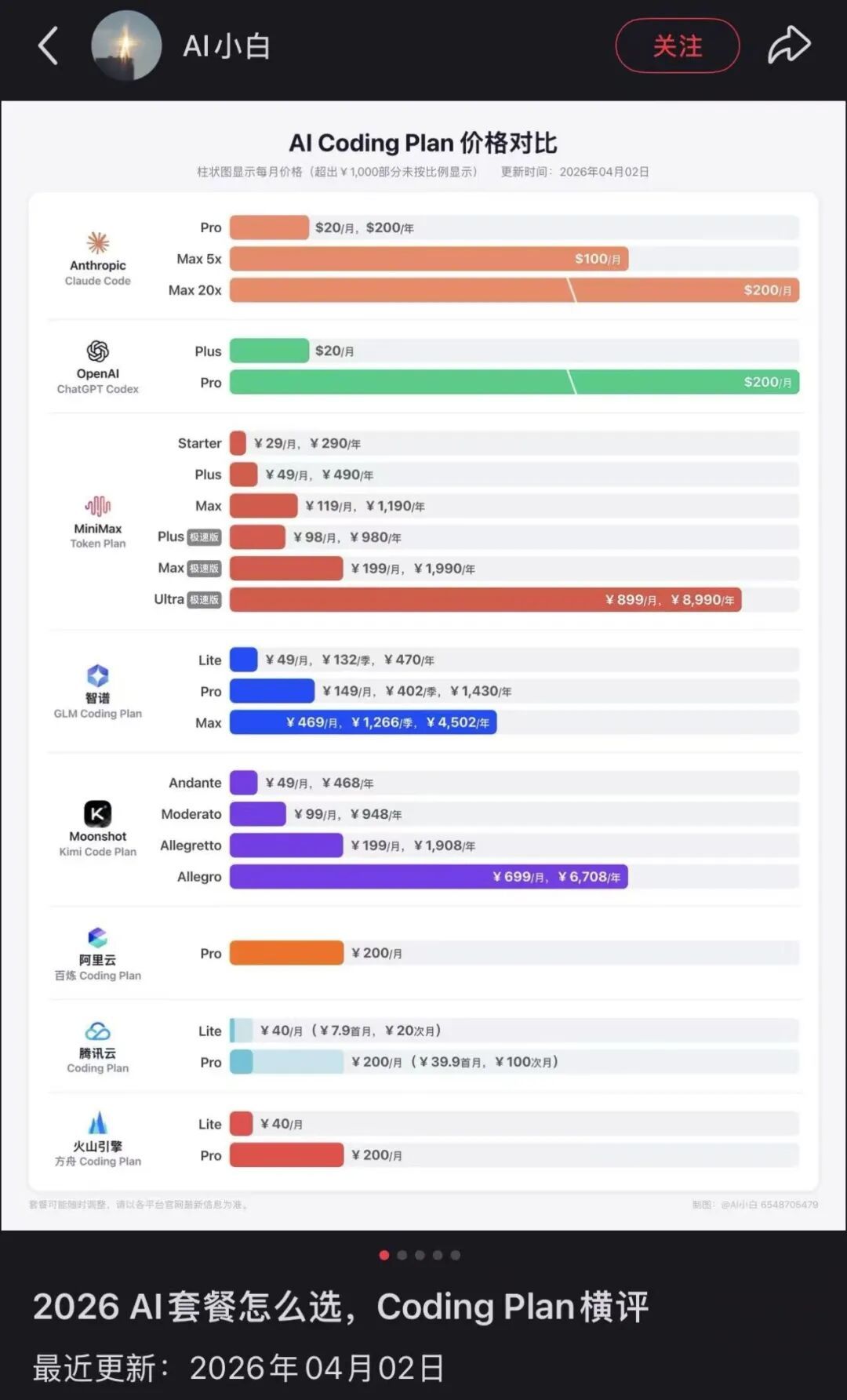
不过,Token计价也并不是唯一的解法,行业内已经在探索一些“另类”的模型收费模式。
一类是按任务收费。比如Anthropic在Claude Code中推出的Code Review功能,直接按一次PR审查计价,单次review平均成本在15–25美元,并随代码规模和复杂度浮动。
二是按结果收费,已经在企业侧落地,比如智能客服、RPA厂商按“问题解决”或“流程完成”计价;还有一种是按时间收费,比如xAI的语音agent按运行时长计费,约0.05美元/分钟)。
几天前,在火山引擎武汉站巡展活动中,当字母AI问及“面对模型调用激增、Token消耗存在不确定性的现状,模型厂商该如何优化定价策略?”时,火山引擎总裁谭待这样回应:
“目前OpenClaw这类通用型平台适合按Token收费,因为其应用场景广泛,无法统一定义效果和成本。”谭待同时表示,未来可能会孵化出垂直领域的智能体,如客服智能体,就可以按回答问题的数量收费。“类似线下找客服的模式,按效果付费。”
“(Anthropic的这一步)大概率是一件好事。Agent时代不属于消耗最多算力的人,而属于最会使用算力的人。”在那篇发文最后,罗福莉这样总结道。
显然,围绕Token收费的争论还将持续下去,这一争论将取决于未来模型-Agent在效率层面的迭代情况。
我们可以确定的是,过去一度被压到几厘钱每Token的单价,在这个调用量激增、链路无限延伸的Agent爆发周期,已经变成了每一个用户都无法忽视的成本因素。
Agent大航海时代,Token收费这笔账,值得每一个厂商认真盘一盘。