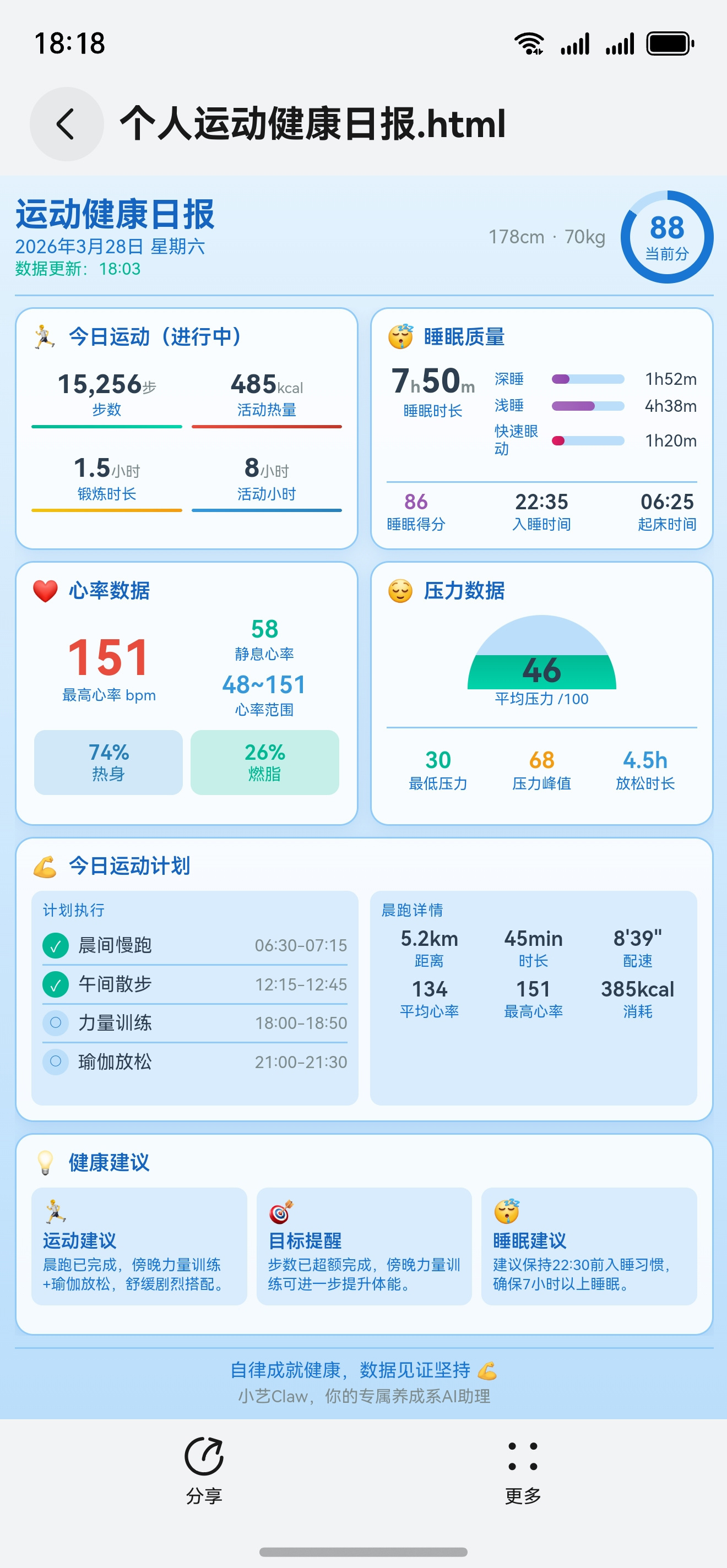
谷歌与OpenAI围绕AI的全方位角逐,是硅谷乃至全球AI行业最重要的战争之一。在去年下半年之前,OpenAI的GPT模型长期压制谷歌;但随着去年11月谷歌发布Gemini 3,它第一次完成了对OpenAI的逆袭。
谷歌AI部门的核心是DeepMind,掌门人则是德米斯·哈萨比斯,一个带有华人血统、曾在剑桥大学就读、追逐AGI顺手拿了诺贝尔化学奖的“别人家的孩子”。
1976年7月,哈萨比斯出生于英国伦敦的一个普通家庭,母亲在商店做售货员,父亲经营一家小玩具店。但在新加坡华人母亲的培养下,哈萨比斯幼年就显露出不同寻常的天赋。
他4岁开始学棋,两周之内下赢了大人。9岁,他成为英国11岁以下国际象棋队的队长。13岁时,他晋升为国际象棋大师,在全球同年龄段选手中排名第二。
16岁那年,哈萨比斯被剑桥大学计算机科学专业录取。随后几年间,他在大学和企业之间不停穿梭,一边在大学里完成学业,一边在企业里探索新技术和产品。
在这一阶段,哈萨比斯在电子游戏中发现了一个令人兴奋的契机——能否让游戏里面的一切角色和物体自主行动,就像他们有自主意识那样?这一理念,与今天的AI存在颇多相通之处;而哈萨比斯也从中逐渐看清了AGI(通用人工智能)这条未来之路。
2010年,哈萨比斯与两位伙伴创立了DeepMind,使命是“解决智能问题,然后用它来解决其他一切问题”。马斯克成为DeepMind的早期投资人。
但哈萨比斯最终选择了谷歌。2014年,DeepMind以4亿美元的价格被谷歌收购。与谷歌两位创始人拉里·佩奇和谢尔盖·布林的志趣相投,是哈萨比斯愿意投入麾下的关键因素。
在谷歌体系内,哈萨比斯带领DeepMind做出了AlphaGo,击败了柯洁、李世石等世界顶尖围棋选手,还推出了可预测蛋白质结构的AI系统AlphaFold。哈萨比斯因此拿下了诺贝尔化学奖,站在了所有科学家梦寐以求的荣誉巅峰。
然而,随着AI大模型时代的到来,哈萨比斯和DeepMind失速了。
为了实现AGI,哈萨比斯执着于在计算机系统内模拟整个真实世界。他在谷歌内部启动了“盖亚”项目,希望模拟自然环境,作为强化学习的试验场。
然而,这场耗资不菲的试验启动两三年后就难以为继,没能产出实际成果。另一边,奥特曼和OpenAI沿着大语言模型的技术路线一路飞驰,最终成为AI大模型时代的第一个大赢家。
哈萨比斯不喜欢奥特曼。在他看来,奥特曼追求权力,而他自己追求知识和科学。但道德评判并不能取代技术和产品的正面对决,哈萨比斯和DeepMind必须奋起直追。
2019年前后,DeepMind开始发力大语言模型。这场追逐战的前半段,OpenAI总是领先DeepMind至少一个档位;但到了2025年,情况开始发生变化。当年底发布的Gemini 3,让DeepMind至少在部分指标追上甚至反超了OpenAI的最新模型。
今年2月,美国知名作家塞巴斯蒂安·马拉比在达沃斯见到了哈萨比斯。马拉比说:“我问近况如何,他说:Gemini现在领先了。说这话时,脸上的笑藏都藏不住。”
这段不可思议的逆袭,是怎样完成的?哈萨比斯起到了怎样的作用?
马拉比刚刚完成了一本新书《哈萨比斯:谷歌AI之脑》。为了这部作品,他花费三年时间,与哈萨比斯累计交流超30小时,并与他身边上百位人士交流数百小时,首次披露了这位DeepMind掌门人诸多不为人知的秘辛。

不久前,《哈萨比斯:谷歌AI之脑》被引进国内,未尽研究创始人、资深媒体人周健工翻译了这本书,他也是中国最早当面采访哈萨比斯的媒体人。字母AI与周健工展开了一场深度对谈,探讨了书中精彩细节,更挖掘了许多未曾公开的幕后故事。

以下为访谈实录(为保证阅读体验,做了少量润色):
字母AI:哈萨比斯具有华人渊源。与另一位华人企业家黄仁勋相比,您觉得两人有何差异?
周健工:哈萨比斯更多的是一位科学家和创新者,黄仁勋的底色更像是一位工程师和企业家,这是两个人基本的不同之处。
哈萨比斯提出AGI的时候,他的构想远远超越了他自己的时代。他在剑桥大学读书时,就萌发了AGI这样一个念头。当年他在伦敦讲AGI(通用人工智能)故事的时候是没有人相信的,即使在硅谷也是极少数人相信。所以他是远远超越时代的。
而且他不是一个简单的科学家,而是想到就要做出来。所以他当初创业做游戏的时候,不是为了做游戏而游戏,而是把它当成一个AI的实验室。
在这一点上,我觉得黄仁勋在创业的时候,也有他的vision(愿景),但是vision并没有超越他那个时代。他可能会超越某个技术浪潮,但是并没有超越时代。
他是被技术浪潮一步一步推着往前走,从显卡到并行计算,到GPU,然后GPU规模越来越大,构建整个AI加速计算的基础设施。
哈萨比斯的vision是远远超越时代的,可能领先于时代十年、二十年,甚至三十年,他在为理想在奋斗,但黄仁勋?他在技术和工程上有他的vision,但是他基本上是一个一个技术浪潮往前走的,我觉得还是非常不一样的。
另外,哈萨比斯虽然有两次创业经历,但是他没有做过盈利公司,更多是一个科学家。他又不是一个简单的科学家,而是一个真正的创新者,不是待在学术机构里面研究AGI。他是科学家加创新者这样的人物。
黄仁勋在企业战略、管理、研发、工程甚至营销方面,是一位非常了不起的企业家,这一点又是哈萨比斯远远比不上。
字母AI:2017年,您和哈萨比斯有一个面对面的交流,现在差不多十年过去,从这本书里,您对哈萨比斯的认知有哪些变化?
周健工:其实很多东西没有改变,比如说他的使命,他说我先解决AI,再用AI解决一切、使命他从头到尾都没有改变。此外,他对AGI的信念没有改变,比如说把AI用于科学发现、造福人类。
同时,他做研究的方式没有改变——高密度的人才组织形式,从全世界各地寻找最优秀的人才进行跨学科的研究。我采访他的时候,DeepMind当时有四五百人,顶尖人才来自全世界60多个国家,今天中国也没有一家这样的公司。他找的都是跨学科的研究人才,研究方法是始终没有变的。DeepMind保持了这样的底色。
还有,他始终在伦敦,即使已经被收购了,即使后来DeepMind和谷歌大脑合并之后,他仍然待在伦敦。
当然也有一些新鲜的东西。他现在领导DeepMind,大概有六七千人,比当年大十倍都不止。他以前是一个比较纯粹的科学家型创新者,但是现在他必须面对从研究到工程、从学术到商业、从发论文到打榜的种种问题。其实他也表现出非常强大的领导力,这是当初他没有展示出来的。
此前和哈萨比斯交流时,他说DeepMind在谷歌AI First战略中起到引领和旗帜的作用。我问谷歌时任CEO埃里克·施密特,DeepMind在谷歌里面究竟扮演什么角色,难道就是收购了一个实验室吗?
他就说了一句——Marketing(营销)。
它当时并没有给谷歌创造出什么业务价值,但是对于整个谷歌的声誉,对于谷歌向AI转型的战略,对于搜罗天下最好的AI人才,它发挥了巨大的作用。
字母AI:在谷歌里面,DeepMind和谷歌产品线没有特别紧密地马上去融合。现在回过头来看,这种想法能不能适应当下的竞争环境?
周健工:哈萨比斯对自己的定位是比较准确的,也是比较符合实际的。DeepMind毕竟是谷歌旗下的一间公司。谷歌给它的定位,其实就是从零到一的突破,就是在AGI的追求上、算法架构科研方面你要不停从零到一的突破。
当然了,怎么样让它规模化,怎么让它和谷歌庞大的生态体系结合?其实不是DeepMind最重要的作用。他把自己首先定位为一个科学家是对的,因为科学家是一个创新和发现型的角色。
谷歌对他最大的期待,是在AI大模型的研究中,你要在与OpenAI的竞争中翻盘,现在Anthropic的势头也很猛。包括面对中国的开源模型的挑战,你怎么保持你的模型的领先性。
我认为这是对哈萨比斯本人、对谷DeepMind歌最重要的一个期待。至于说你赚多少钱,用在我的搜索还是用在我的邮箱里,或者说你自己变成杀手级的应用或者是怎么样,其实这不是他最重要的问题。
字母AI:哈萨比斯早年间做游戏的经历,对他后来做AI有什么直接的影响吗?
周健工:他在剑桥大学读书的时候,他已经有过在游戏公司打工的一段经历。他在那个牛蛙实验室里面,尝试了很多创新,里面有几个故事很有意思。比如说他们会设计大量的游戏里面的角色和环境的互动,这些互动和反馈,其实就是智能体的一些最初级的概念。
里面还有一个情节特别有意思,他那个老板(莫里纽克斯)就带着他去卡内基梅隆大学——当时是AI研究的重镇,跟研究AI的教授们聊,教授们就拿出一些很简单的理论化、抽象化的AI智能体的概念跟他们讲。
当时哈萨比斯立刻就觉得,其实你在讲的东西,我已经开始在做了。给了他非常大的自信。
他离开剑桥的时候,AGI的概念,他基本上在脑子里已经形成了。他们后来自己创办了一家万灵药工作室,做了一个叫《共和国》的游戏,非常复杂。他在1999年就想把机器里面的螺丝的纹理、台阶上苔藓的纹理都渲染出来,想刻画1000多个形象,要从游戏的有限状态中进入一个无限状态,但远远超越了他们那个时代的水平,因为当时的整个算力是根本不够的。
他们去美国博览会演示游戏,计算机偷偷加了八倍的显卡,但是到最后演示的时候还是崩溃了,掉链子了。这说明,他的游戏想法远远超越了他那个时代的技术基础,但我相信这个经历,对他未来能更切实际地追求AGI的影响也是巨大的。
无论是在做游戏的公司打工还是创业,都证明了他是知行合一的科学家。他研究AGI,不是在一个学术环境里面做,而是要为他的AGI找到一个实验的环境,那么实验的环境最初就是游戏。
字母AI:19年的时候,OpenAI的一个高管跟哈萨比斯说,如果有任何一方接近了AGI的话,就可以开展合作什么的,但当时哈萨比斯就拒绝了。哈萨比斯的选择,您觉得是利大于弊,还是弊大于利?
周健工:我觉得是不可能去合作的。
第一个就是哈萨比斯认为,AGI只能通过强化学习实现,再加上一些神经网络,因为他研究生物神经计算。所以在当时他不可能跟OpenAI合作,来自他早期固有的想法,他采用的是单一模型的、排他的路线,走强化学习,而OpenAI他们主要走的是深度学习的道路。
另外一点,哈萨比斯内心还是有孤傲的一面,一直到那个时候,他内心还是觉得OpenAI只是自己的一个追随者和模仿者,他肯定是不屑于跟他们合作的。
其实,当时的AI圈子,在研究的层面还是比较开放的,不管是DeepMind还是谷歌大脑,包括transformer论文,他们都会马上就公开。在研究方面没有什么可合作的,主要是在工程实践上,他们后来慢慢产生了很大的差异性。
字母AI:DeepMind之前为了实现AGI,就启动了一个叫盖亚的项目,在计算机里面去模拟一个真实存在的世界,然后在世界里面再做一些智能体,然后慢慢地去把AI给训练出来。
周健工:你可以这样理解,因为在他们做盖亚的时候,AlphaGo已经攻克了围棋,他们就觉得在研究AGI的领域,已经在游戏方面取得了辉煌的胜利——围棋这一最复杂的智力游戏都攻克了。他们肯定会寻找下一个目标,游戏只是一个实验环境而已。
他们也看到了围棋作为实验环境的局限性,它是一个361个方格的棋盘,有清晰的边界、明确的规则,这些都非常局限。自然界是连续的、复杂的,是模糊的、高维的,和游戏的环境是非常不一样的。
所以你要真正证明自己是AGI,必须把它放到自然环境中验证。所以当时他们就想到了要做盖亚项目。
盖亚项目在当时进行了两三年,其实并不成功,现在实现起来仍很困难。当时这是一个非常超前的项目,但在学术研究上绝对有价值。
对DeepMind来说,他们永远不是以发论文为目的,而是发论文之后,过一段时间就要把它做出来,但是他们一直没有把它做出来,我觉得的确是非常超前的,但是探索是很有价值的。
字母AI:谷歌几年前花了一点钱收购了DeepMind,当时有几家公司都在竞购,包括扎克伯格这样的人,但是最后哈萨比斯还是选择了谷歌。在您看来,哈萨比斯在那个时间点上最看重谷歌的因素是什么?
周健工:我觉得首先谷歌当然是最成功的互联网公司。在当时2013年、2014年的时候,它已经是非常赚钱的一个公司,实力很雄厚。谷歌作为一个搜索公司,又是在所有的互联网公司里面对AI最有vision的,也非常重视AGI,这是哈萨比斯特别看重的一点,这是第一点。
第二,谷歌的文化,他认为谷歌的两位创始人谢尔盖·布林和拉里·佩奇,他们身上还是有一些科学家的气质的,都是斯坦福的博士毕业生。其实他们对于科学探索会有一些长远的布局,比如谷歌X实验室,涉及许多前沿领域。当时他们刚开始做自动驾驶,他们认为可以把DeepMind定位成一个探索未来型的机构,其实谷歌是可以容得下他们的。
另外一点,就是说谷歌其实对AI技术、未来技术的伦理和安全是有这个意识的。不管怎么说,谷歌当时还是提出了自己不作恶的文化,其实他们在价值观上有相通的地方。所以,谷歌一开始就是哈萨比斯的首选。
在过程当中,马斯克也想收购他,但是哈萨比斯很清楚马斯克没有实力,而且有自己的私心。马斯克说,我带着你去探索,比如探索外太空、星际移民之类的。哈萨比斯就会认为你和AGI不完全是一回事,我不能成为你那个东西的工具。
当时扎克伯格也找过,他跟扎克伯格聊完之后,觉得扎克伯格对AGI的认识远远不如谷歌深刻。
最后还是一个决定性的因素,有一次,拉里·佩奇拉着他出去散步,然后就说你的目标不是想研究AGI吗?那你为什么不来谷歌,我这里已经为你准备好了一切。就是一句话立刻打动了他,完全说服了他。
字母AI:DeepMind进入谷歌,在大语言模型时代到来之后,反而在一定时期内被OpenAI甩在了后面。哈萨比斯对DeepMind有什么比较大的影响吗?他选择了一条在我看来可能有点过于超前的路,导致被很快甩开。
周健工:因为他们进入谷歌的时候,人也多了,算力也多了,钱也多了,资源也多,他们本身就在探索不同的项目和路线,我觉得是很正常。
哈萨比斯他自己的战略判断上,我觉得在那个时候出现了一些偏差,也可以说是一定的失误吧。就是他不重视大语言模型,就是他自己在内部讲过,我们的研究的布局是三个,第一个就是强化学习,他把强化学习摆在第一位;第二个就是神经网络。第三个是基于数据的归纳推理之类的东西,然后他把语言又看成第三个里面一个分支,这就可以看得出来,他战略上是不重视大语言模型。
他更相信强化学习。另外一方面,他认为语言作为一个数据的来源,特别是不接地气的,都是一些抽象的这些东西,但是他其实低估了在移动互联网的发展到那个程度的情况下,语言数 据可用于训练大模型、当时的GPU算力一直在突飞猛进,两者可以完美地结合,可能带来一种新的突破。
他真正开始重视的时候,是GPT-2出来之后。大家都说OpenAI在做一个GPT-3,参数量好像是1750亿。达到那个量级,他们才开始重视,但时候已经有点晚了。
当时DeepMind在研究一个模型叫麻雀(sparrow),基于Chinchilla基础模型,700亿参数,但拥有最先进的saling law方法;与此同时,谷歌大脑在研究好几个模型,如Gopher、LaMDA、PaLM等,最大的大概有四五千亿参数,当时谷歌认为这下就能就超过GPT-3了,你就1750亿,但是他没想到OpenAI中间能弄出个GPT-3.5,就是ChatGPT那个模型。
同时,2022年的夏天GPT-4的预训练已经基本完成了,大概接近2万亿的参数了,当你去盯着GPT-3去追赶的时候,别人已经开始基本上把GPT-4给弄成了,那你完全处于一种被动挨打的状态。
字母AI:DeepMind被谷歌收购几年之后,双方的关系就开始有了一个比较大的裂痕,您觉得有什么样的生成的原因,哈萨比斯在里边又起到什么样的作用?
周健工:这是一个特殊情况下的博弈。我觉得很难说是一种冲突,哈萨比斯不是想挑起跟谷歌冲突的人。
谷歌对于DeepMind始终是非常重视的。它对DeepMind是全力的算力倾斜,DeepMind做很多超前的研究都需要耗费大量的算力,反复地实验和训练,还有很多失败的模型,耗费巨大,一个DeepMind的算力比整个Gmail用的算力都多。而Gmail在全世界有几十亿用户。
为什么说它是在一个特殊情况下的博弈?当时谷歌在上面一层成立一个控股公司叫Alphabet,想把一些长期投入、目前还不需要不赚钱的项目分拆出去,可以到外面去融资。
所以当时DeepMind其实是处在这样一个位置,哈萨比斯团队本能地就想,那我是不是分拆出去,或者说高层是不是想把我分拆出去,我分拆出去我怎么办?大家都在想自己下一步的打算。
但是谷歌对DeepMind非常重视,承诺未来十年给它150亿美元继续研究AI,但是联合创始人苏莱曼就想得比较多,他觉得是不是一个机会,我们就把它独立出去,再到外面找一些主要的投资人。他们还找了蔡崇信,找了LinkedIn的创始人霍夫曼。霍夫曼说我答应给你十亿美元,他们想再找几个,但没找到。
谷歌内部对于DeepMind的未来的定位,当时也有一些摇摆。拉里·佩奇当时说你愿意分拆出去,我可以给你很多钱,你继续研究。但是新任谷歌CEO桑达尔・皮查伊(Sundar Pichai)的想法不一样。
上层的想法不一样,下面的人就要考虑自己的出路了,所以当时他们有一个马里奥计划,就是与母公司博弈,想办法分拆出去。
后来皮查伊就决定不能分拆。他们最终以战略的眼光看待DeepMind所研究的AGI,认为它将决定谷歌的未来。从这一点来说,谷歌一直是抱定对哈萨比斯信心的。
从某种意义上,DeepMind在谷歌内部的关系最终理顺了。因为谷歌是个大公司,在工程和产品上肯定没有初创公司快,但是谷歌的研究能力还是非常强大的,包括后来研究TPU芯片,他们在基础设施方面其实很早就投入了。
所以,我觉得哈萨比斯本人在AI的大规模工程部署,商业竞争,产品的开发,这些能力和成就,也是在谷歌平台上才能够成长和放大的。所以我觉得是一个相互成就。
字母AI:DeepMind从GPT-3就开始追赶,但去年之前,谷歌的Gemini,相比OpenAI还是有一定的差距的,直到去年开始有一些逆袭的迹象,您觉得之前那几年时间里,为什么DeepMind面对OpenAI屡战屡败?
周健工:第一个,就是说你在技术节奏上就比别人慢一拍到两拍了。
从大模型来看,当OpenAI发布ChatGPT时,GPT-4已经预训练训练完成了,第二年3月份就完成后训练并发布了。
DeepMind和谷歌大脑他们各自做的大模型,其实都瞄着GPT-3打,但当时人家内部已经有GPT-4了。尤其是3月份人家发的时候,你的技术确实比别人落后了一代。
第二点,ChatGPT的确是硅谷历史上最成功的科技产品,它当时很快占领了用户的心智。
AI虽然已经发展了70年了,但是它始终是在一个象牙塔,一个小圈子里。ChatGPT出来之后,它突然进入大众和主流人群了。对于占据用户的心智,一直到今天,它起到一个强大的作用。
OpenAI的最大优势就是ChatGPT在几年之内变成了AI的代名词。周活达到九个亿了,今年破十个亿肯定是没有问题。现在Gemini从规模到性能打榜再超过别人,但作为一个独立的AI应用,用户数还是不如别人。
还有就是大公司病,当时谷歌彻底暴露了。特别是开源模型Llama很快又推出来了。当时谷歌团队内部有一句令行业很震惊的话,大模型根本没有护城河。Llama推出来之后,谷歌内部就是乱作一团,产生了危机感,连创始人都回办公室上班了,他本来觉得自己已经退休了。
还有一个方面,DeepMind的架构做调整的过程,它是有一个适应的,它是有过渡的一个过程,中间经历了Bard模型灾难性的发布。最后把谷歌大脑与DeepMind合并,由哈萨比斯负责 ,并集全公司之力构建统一的大模型Gemini,个调整过程这耗费了半年左右的时间。
统一之后,他们开始专心致志地去做Gemini,然后2025年年底才算是初步实现翻盘。
字母AI:在此过程中,相比DeepMind之前那些事情,你觉得他主要的成功的因素是哪些?
周健工:哈萨比斯一旦想赢得一场竞争的时候,其实他是非常善于做这些事情的。以往,他想做什么,基本上都做出来了,你只要给他足够的时间和资源,他基本上都能做出来。
我觉得有一点很重要,是谷歌的基础设施对他的保障。整个TPU架构始终在推理和训练方面支撑着发展。
它不光是算力够,还有软硬件的协同,TPU新的架构要怎么适配新的模型,下一步的技术的亮点怎么可以通过硬件实现,怎么从TPU或者算力架构里面去最有效地去榨取它的算力,其实这些都是非常重要的,因为在一家公司里面,模型与基础设施配合得很好,直到最后TPU而不是GPU训练出了最强的大模型Gemini-3。
还有一个,谷歌人才是相对来说比较稳定,资金也比较稳定,不像OpenAI后来不停地去融钱,而且只有自己的基础设施,商业模式可能才成立,这一方面DeepMind没有这些后顾之忧了,专心致志去把Gemini大模型给做好,原生多模态上也好,长上下文也好,持续学习也好,世界模型也好,可以没有后顾之忧去探索这些。本来这些方向和研究上是他们擅长的地方嘛,所以他把优势就可以发挥出来了,我觉得专注也是一个非常重要的作用。
字母AI:在此过程中,哈萨比斯个人起到了一个什么样的作用?
周健工:他是整个谷歌AI的代言人,是整个谷歌的AI的灵魂。
尤其是他获得了诺贝尔奖之后,他对AI的发展的方向的看法就更加容易让人们信任。他是一个科学家,生物科技、药物发现这些都是对人类未来的福祉有重大影响的,所以他对于谷歌AI获取公众的信任这方面,起了非常大的作用。
但另一方面,哈萨比斯不太相信量子计算。他认为图灵机——也就是经典计算——能够解决AGI所需要的基本计算。这对于他将来在谷歌的发展,我觉得一个潜在影响因素。
我们知道谷歌对量子计算非常重视,最近皮查伊高调宣布,量子计算很可能近几年有重大突破。所以,如果哈萨比斯不相信,或者怀疑量子计算个真的能起到那么大作用,那么他将来能不能在谷歌DeepMind包容量子计算,也值得关注。
字母AI:你觉得他现在是一个合格的企业家吗?
周健工:我觉得哈萨比斯可能是重新定义了科学研究的创新者。这一评价一点都不比企业家要低,他改变了很多做科学研究的这种方法和范式。
其实我在采访他的时候就非常好奇,我说你整天做这些研究,但是你作为一个初创公司,你的投资人要让你赚钱,难道你的投资人就看你发paper吗?
他说一开始的想法就是去用发现AI理解宇宙,解释周围环境的结构、底层运作的逻辑。我没有办法超越费曼,没有办法超越爱因斯坦,但是我要发明的AI将来能够超越费曼,超越爱因斯坦。
他的做法是通过创业的方式来实现研究的突破,一开始他是非常讨厌学术机构的,他认为学术机构有官僚气息,没有紧迫感,处于一种散养的状态。你研究AGI,今天机构发一篇论文,那个机构发一篇论文,这样无法实现突破。
因为哈萨比斯对自己有一个使命感,要用毕生的精力、用这一生把AI做出来。这种用创业的心态去做科研,用AI的方式去做科学突破,是改变了整个科学研究的方法和范式的。
我认为,他甚至比作为一个单纯的企业家的意义更大。
字母AI:长期来看,哈萨比斯是带领DeepMind继续往前走的最合适的人选吗?
周健工:哈萨比斯给自己设定的目标是AI的实现,而不是说在谷歌当个什么,比如说他有一天是不是取代皮查伊当谷歌的CEO,这根本不是他的目的,尽管有人做过这种猜测,但我认为这即不是他的兴趣,也不是他最擅长的。
我觉得哈萨比斯唯一的目标就是实现AGI。他自己说,还需要五到十年,还缺一两个transformer级别的创新。而且他还是继续在谷歌DeepMind上来做,这依然是他最好的一个平台吧,至少在未来的三到五年,我认为是这样的。