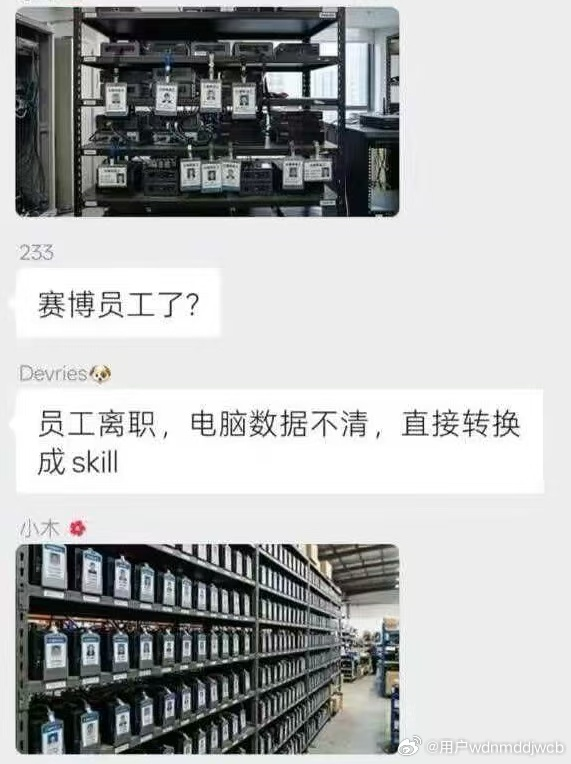
新智元报道
编辑:倾倾
【新智元导读】OpenAI根本没有护城河!顶级分析师Benedict Evans判断:大模型本质上是「大宗商品」,OpenAI极有可能重演Netscape的悲剧。80%的用户一年交互不足千次、Meta掏出50%的收入去买芯片,AI行业的「财务重力」时刻已经到来。
不要再幻想OpenAI会成为下一个谷歌或微软!
在最新一期的The MAD Podcast中,顶级科技分析师Benedict Evans与Matt Turck进行了一场长达一小时的硬核博弈。

Evans给出结论:OpenAI面临着毁灭性的护城河危机。
与Windows和谷歌不同,基础模型目前展现出的特质是极度昂贵,却又极度同质化。
现在的OpenAI有9亿周活用户,但80%的用户一年点击回车键的次数不到1000 次。
显然,AI 行业的财务已经紧绷到了极限。

消失的护城河:大模型只是「大宗商品」?
科技史上所有的垄断,都建立在网络上。
你用Windows,是因为开发者在为Windows写软件;你用谷歌,是因为它的搜索结果随着用户点击而不断优化。
但在大模型领域,这种逻辑失效了。
Evans指出,目前没有任何证据表明,一个领先的模型能够阻止竞争对手做出同样好的模型。
Claude、Gemini、Llama正在疯狂接替领跑员的位置,每隔几周就会出现一次王位易主。
如果你是Sam Altman,你手里拿着的是一种大宗商品技术
Evans 说道。OpenAI没有自己的基础设施,没有差异化的网络效应,有的只是巨大的「心理份额」。
这像极了1995年的Netscape(网景)。
当时Netscape拥有全世界最好的浏览器,拥有最高的关注度。
但当浏览器本身变成一种基础设施,当拥有流量和系统的巨头反应过来时,缺乏护城河的先驱者会迅速被吞噬。
现在的OpenAI正拼命地想用这份心理份额去兑换硬资产。
一英里宽,一英尺深:ChatGPT 的真实使用困境
通过对Reddit上数千名用户分享的年度总结数据进行抓取,Evans发现了一个惊人的规律:绝大多数用户平均每天与AI的交互次数不足3次!
如果你去年在ChatGPT里输入过1000条指令,那么你已经是全球前20%的硬核用户了。

对于普通人来说,ChatGPT只是一个偶尔好用的搜索增强器或文案改写器,而不是生产力中枢。
这种低频使用的后果是,只有不到5%的用户愿意为此付费。
Evans提出了一个深刻的洞见:仅仅让模型「变得更好」是解决不了问题的。
如果你问AI 50个问题,上个月它错了10个,你得检查一遍;这个月它错了8个,你还是得检查一遍。
从90%的准确率提升到95%,都需要人类介入检查。
除非AI能进化到绝对正确,否则它就无法真正从人类的工作流中解放出价值。
财务重力时刻:Meta 50% 收入买芯片的豪赌
AI竞赛已经进入了「大力出奇迹」的深水区,随之而来的是失控的财务数据。
Meta最新的财报显示,其资本开支预计将占据总收入的50%以上。

Evans惊叹道:
这可不是利润的 50%,而是总收入的 50%!
即便强如谷歌和微软,也在以双位数百分比的速度增加资本开支。
这种投入规模已经超越了建造工厂,更像是建造一个国家的基础设施。
然而,这种投入是否能换回等比例的产出?
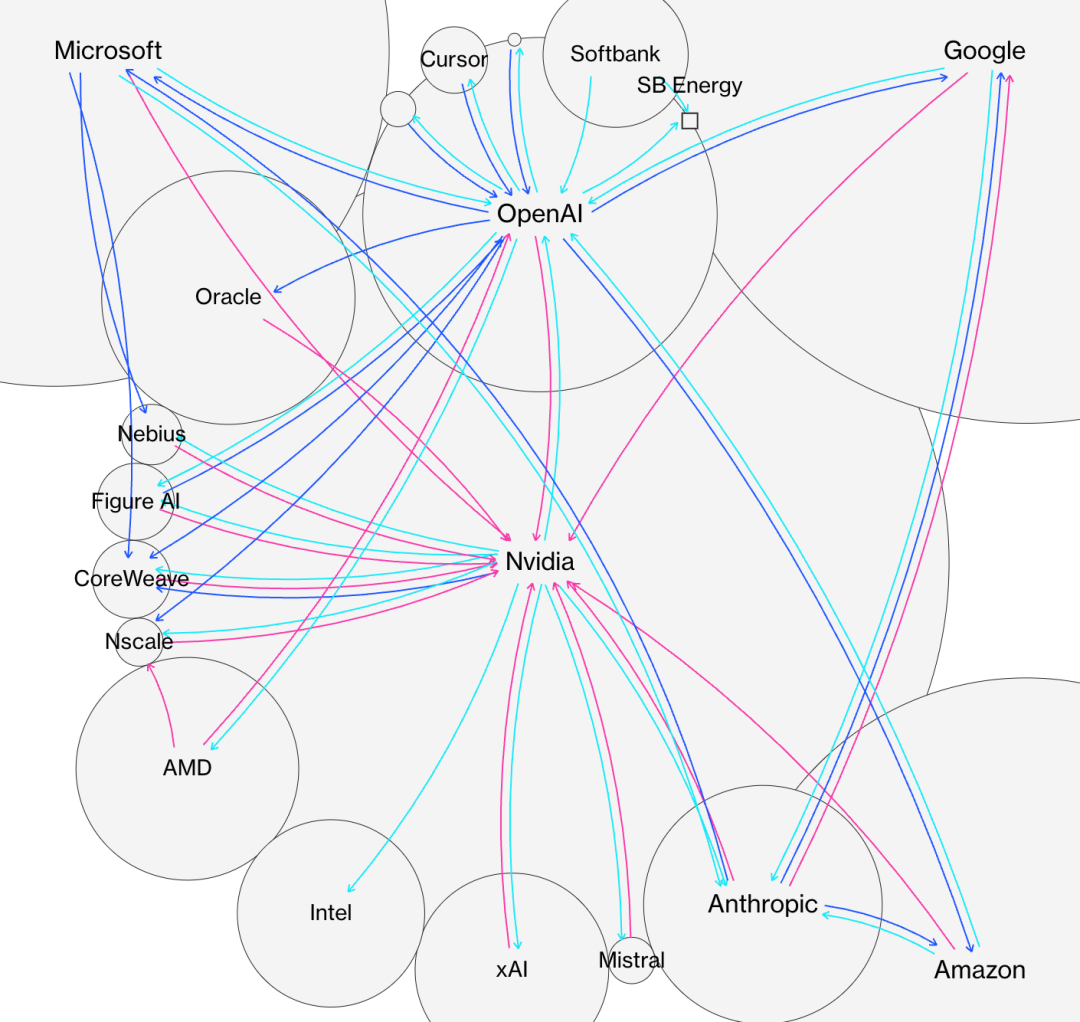
目前AI行业的收入结构中,存在着大量的循环收入和供应商融资。
英伟达把芯片卖给云服务商,云服务商再把算力租给AI初创公司,而初创公司的融资往往又来自这些巨头。
这种左手倒右手的游戏,掩盖了真实市场需求的疲软。
软件的「即兴」革命:SAP会被取代吗?
在谈到 AI 对软件行业的冲击时,Evans 提出了一个新的分类法:即兴软件vs 制度化软件。
在他看来,每个人都会给自己写一个专属ERP的想法纯属幻觉。
大公司需要的是像SAP、Oracle这样稳健、合规、标准化的系统,不可能交给一个随性的AI代理去随机发挥。
过去,很多琐碎的业务流程因为规模太小,不值得雇程序员去开发专用工具,人们只能用Excel和邮件肉搏。
现在,AI让代码成本降到了近乎零,AI正在将大量的非标工作软件化。
这并不是说软件行业会萎缩。相反,根据杰文斯悖论,当资源的利用效率提高时,人们对该资源的总需求反而会增加。
我们会拥有更多的软件,而不是更少。Evans 认为。但软件公司的溢价能力将从「写代码」转移到「对业务痛点的深度理解」。
如果你只是一个简单的数据库包装器,那么你很快就会在 AI 的代码洪流中溺亡。
1997 vs 2026:AI的「Netscape时刻」
回顾历史,1997年的互联网正处于最疯狂的前夜。
当时的人们预测到了电商、视频会议和移动互联网,但他们绝没有预测到Uber。
我们知道AI很重要,所有的巨头都在往里砸钱,但我们还在用把PDF搬到网上的思维在做AI社交。
真正的AI原生应用尚未出现。
OpenAI正在尝试通过OpenClaw等代理工具寻找新的增长点,但这让它直接撞上了谷歌和苹果的枪口。
当AI试图接管用户的桌面和收件箱时,隐私、权限和系统的控制权,将成为比算法更难逾越的鸿沟。
这波浪潮中,一定会有公司赚到大钱,但可能不是因为算法跑分高。