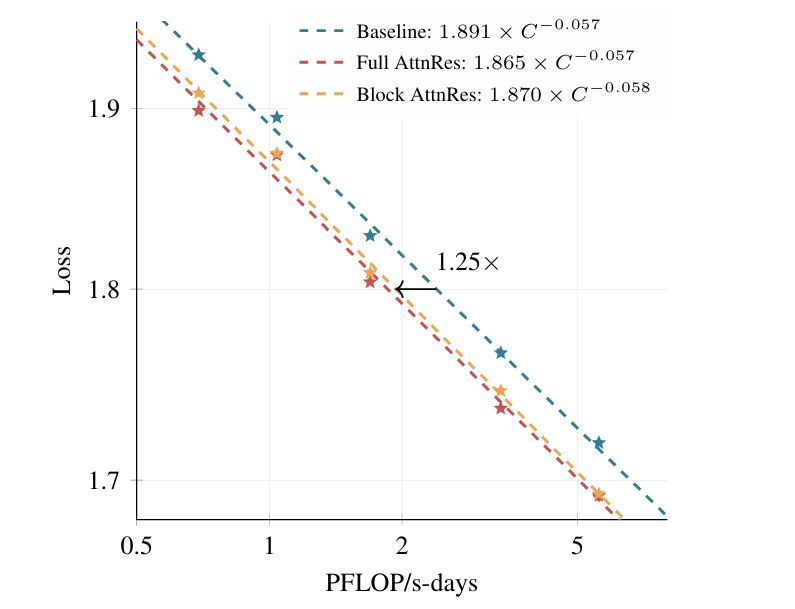
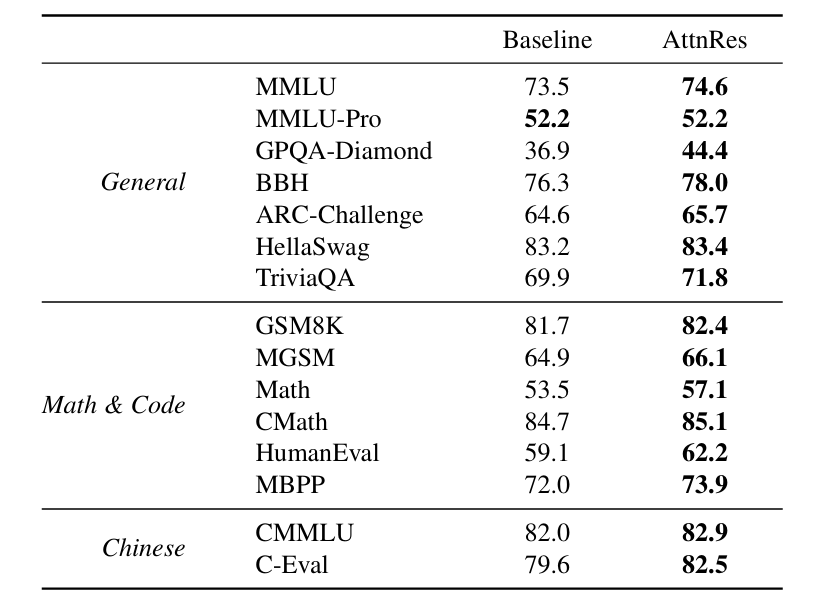
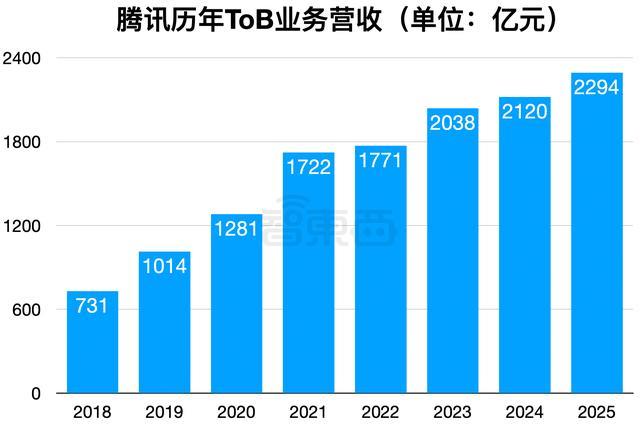
我们播客的合作者姚嘉在最近这期节目里有一个很有趣的洞察,他把这称作AI创业大潮中的“老头乐现象”:
在这一轮AI革命中弄潮的,很多都是四五十岁的中年人,比如OpenAI 的 Altman,41 岁,Anthropic 的 Amodei,42 岁;DeepMind 的 Hassabis,48 岁。最近大红大紫的OpenClaw的开发者Steinberger,38 岁,都已经退休过一回了。
这个现象放在中国也有类似情况,智谱AI的张鹏44岁,DeepSeek的梁文锋41岁,阶跃星辰的姜大昕40岁,MiniMax闫俊杰也37岁了!
当然要说这群人是“老头乐”,那也有点伤人。不过说是中年革命,应该不过分。这跟30年前的互联网革命有很大不同,那几乎是一个辍学生和穿帽衫的男孩们统治的时代。
没人会真的把这群掌控千亿市值、定义技术走向的人称作“老头”,但姚嘉的调侃里藏着核心事实:本轮AI革命的话语权,牢牢掌握在中年人的手中。
当我们切开一个个AI项目的外壳,会发现这场革命的底层逻辑,从一开始就注定了——它偏爱相对更有积累、有情商、有敬畏心的中年人。这种权力的移转并非偶然,也与运气、情怀、年龄歧视没什么关系。

互联网是快消品,AI是重工业
创业类型有很多,但互联网创业的逻辑经历了30年的造富效应,最为人所熟知:找痛点、搭团队、快速迭代、冲高流量、抬高估值、上市变现,在某个赛道牢牢占据一块市场。
但在新的这轮AI创业浪潮中,无论是资源密集度的门槛,还是宏观经济周期的改变,加上监管环境、公众舆论对创业者的要求,都与互联网革命不可同日而语。
先看资金门槛,如果说互联网革命是生产洗衣粉的轻工业,AI革命就是生产万吨乙烯的大基建。
互联网刚刚萌芽时,创业成本低到惊人。几台廉价服务器、一个创业点子、几个同学伙伴,就能在车库中、宿舍里启动一个项目。
扎克伯格在哈佛宿舍搞Facebook,启动资金2000美元;马云创办阿里巴巴,启动资金靠“18罗汉”凑一凑,50万元人民币。那时候的创业,拼的是“敢想敢干”,资金从来不是最大的绊脚石。
AI创业则是另一番景象——它是资本密集型的“重工业竞赛”,没有巨额资金,连入场券都拿不到。训练一个领先的基座模型,需要数以万计的GPU、极高的电力供应,以及数亿甚至数十亿美元的持续投入。
巴克莱银行有个分析,AI基础设施的资本开支已进入超常增长阶段,预计到2030年,仅美国数据中心的电力需求就将比目前增长三倍,达到每年5600亿度电——等于新增了三个三峡大坝的发电量。
中国在本轮AI革命中主打一个价格便宜量又足,但这并不意味着中国的AI项目可以轻资产投入。以港股上市公司智谱为例,他们训练GLM-130B大模型时,使用96台DGX-A100(每台8×40G),预训练持续60天,等价于花费490万美元的云服务费用。
这还只是一个版本模型训练的基础费用与时长!
梁文锋的DeepSeek-V3模型,算是“低成本高效益”的典范,仅为GPT-4估算成本的二十分之一到十分之一,但训练成本依然达到557.6万美元。如果没有幻方量化数百亿规模、几十个百分点年收益率所形成的资金池,也无法支撑这样的研发投入。这种规模的资金门槛,绝大多数年轻创业者都无法承担。

资金之外,工程经验的门槛,也把大多数年轻人挡在了门外。
互联网创业的技术门槛相对较低,只要能快速实现MVP(最小可行产品),就能获得市场反馈、持续迭代。但AI创业不一样,大模型训练涉及分布式系统、优化算法、数据工程、硬件适配,每个环节都需要深厚的工程经验,每一步都不能出错。
还拿智谱AI举例。根据团队开源的研发时间线,GLM130B从2022年初开始进行多平台适配、算法与框架调试、数据准备和大规模测试,正式持续的预训练仅在5-7月这三个月内完成,大部分时间都用于“适应性调整和系统调整”,真正稳定训练的时间不到2个月。
这种“踩坑-填坑”的过程,与互联网时代的小步快跑、快速迭代格格不入,反而更类似于传统的工程建设。
姜大昕的经历也印证了这一点。这位47岁的阶跃星辰创始人,出身于微软亚研院,在自然语言处理、机器学习领域积累了数十年经验,是多个顶级会议的区域主席和期刊编委。

他创立阶跃星辰后,选择了“多模态统一”的技术路线——不是简单拼接不同模态模型,而是从架构层面实现原生融合。这种高难度的技术选择,需要对技术边界有清醒的认知,更需要深厚的工程功底,而这两种功力的积累都需要漫长的时间。
组织能力和人脉资源,更是中年创业者的“独家优势”。
互联网创业初期,团队规模小,管理简单,年轻人靠热情和冲劲就能带动团队。但AI创业需要的是规模化的组织管理,需要协调科研、工程、市场、资本等多个环节,需要整合学术、产业、资本等多方资源——这些能力,只能在长期的职业积累中慢慢沉淀。
张鹏的“清华系”网络,就是最好的例子。他在清华深耕二十余年,积累了强大的学术网络和产业资源,智谱AI的董事长刘德兵、首席科学家唐杰均为清华系人士,许多清华校友甚至辞掉国外顶级公司的工作,加入智谱AI。这种强大的人才感召力,不是年轻创业者能复制的。

闫俊杰虽然年仅37岁,处于中年与青年的边界,但他的组织能力同样来自长期积累。在商汤科技担任副总裁期间,他见证了“AI四小龙”的辉煌与困境,深刻理解上一代AI落地的痛点。创立MiniMax后,他打造了一支平均年龄29岁的年轻团队,却能凭借自己的管理经验,实现扁平化管理,让团队快速迭代产品,最终仅用4年就完成上市,刷新了AI公司的上市速度纪录。

说到底,互联网创业是“点子驱动”,AI创业是“积累驱动”。年轻人或许有更好的点子,但中年人有足够的资金、经验、人脉和组织能力,能把点子变成真正的技术、真正的产品、真正的商业价值。这不是年龄的胜利,而是积累的胜利。

资本也学会品尝时间的滋味
资本也是决定创业风向的重要一极。AI时代中年人能掌权,很大程度上,是资本的外部环境与行为模式发生了根本转变。
互联网时代,资本的主要玩法是普遍撒网、覆盖赛道,赛马中的领先者获得更高倍率的资本追投,直到上市套现。YC开创的5万美元占5%股份的玩法是这一潮流的集大成者,VC愿意把钱投给大量年轻创业者——哪怕他们没有经验、没有盈利模式,只要有一个概念足以让后面几轮投资者愿意接盘,资金就会纷至沓来。
杨致远、拉里佩奇、扎克伯格,这些杰出的年轻人奠定了这一模式的基础。直到Uber的超长规模融资难以为继,和WeWork带来的击鼓传花的破裂,这一模式终于失去了光环。
WeWork泡沫破裂、全球化被特朗普中止,加上疫情的冲击和元宇宙的伪命题,资本开始变得小心翼翼起来,LP(有限合伙人)对风险溢价的要求更高,VC再也不敢“广撒网、博概率”,而是转向“精挑细选、选赢家”。他们的投资逻辑,从“赌未来”变成了“求确定性”。而这种确定性,恰恰是中年创业者能提供的。
投资机构Antler做过一个统计,2021年,AI独角兽创始人的平均年龄达到了40岁的峰值。在真正具有高护城河的核心基座模型领域,经验的溢价依然存在,VC的资金依然优先流向那些拥有“深厚履历”的中年人。
OpenAI、Anthropic、xAI等头部初创公司的核心团队,几乎清一色是曾在谷歌、Meta或顶级研究机构沉淀超过十年的“老兵”。Sam Altman能拿到巨额融资,离不开他在Y Combinator担任总裁期间建立的投资人网络;Dario Amodei创立Anthropic后,能快速获得资本青睐,得益于他在OpenAI主导GPT-2、GPT-3安全评估的深厚经验;Demis Hassabis的DeepMind,能被谷歌以6.5亿美元收购,更是因为他在AI领域的长期积累和跨界视野。
VC对创业者的评估维度,也发生了彻底的转变。
互联网时代,VC最看重的是创业者“快速实现MVP的能力”,行业经验、资本调动能力都不是必需品,甚至偏好“外行颠覆者”。但在AI时代,资本的评估标准完全反转:他们更看重创业者的深层R&D背景、大规模算力管理经验,看重他们对垂直行业的深层认知,看重他们处理复杂算力合约、电力供应的能力,看重他们获取优质数据、算法专利、合规壁垒的能力。
在临门一脚的资本退出路径方面,AI时代的资本也更偏向中年创业者。互联网时代,VC主要依靠IPO退出,而AI时代,私募股权融资和巨头并购整合成为更为主流的退出方式——微软收购Nuance、入股OpenAI,谷歌收购DeepMind,都是典型案例。
在中国也有类似情况,基座大模型的主要玩家基本是字节、阿里这类超级巨头,即使有一些创业公司诞生,但大公司的战略投资也早早找上门去。
VC的算盘变了,创业的风向自然也变了。当资本不再追着“少年天才”跑,而是围着有积累、有确定性的中年人转,AI革命的话语权,自然就落到了中年人的手中。


反应过来的监管与媒体不再听之任之
如果说资本转向是“推力”,那么监管收紧和媒体叙事转变,就是“拉力”——它们共同将中年人推向了AI革命的前台。
互联网革命的来临,有很强的“猝不及防”意味。正如马云所说,“当年你爱搭不理,后来就高攀不起”。起于草莽的互联网产业,早期很像年轻人的玩闹,甚至诞生了给beg(乞讨)加个“.com”后缀就能上市薅钱的段子。
各国监管层对这种前所未有的事物抱持宽容的态度,媒体也更愿意报道少年英雄改变世界的吸睛故事(虽然后来更多的仅仅是少年暴富)。
但是经历过“颜色革命”、社会撕裂、贸易战、全球大流行之后,互联网对社会结构的深刻改变暴露无遗,无论是监管层还是媒体,对新的技术革命都更加审慎起来。
面对AI伦理、数据隐私、算法公平,这些监管要求,需要创业者不仅要有技术,还要懂政策、懂法律,且有足够的社会责任感。年轻人或许敢“先上车后补票”,但中年人更清楚,一旦触碰监管红线,所有的努力都将面临不可预测的未来。
所以在OpenAI如日中天的时候,仅仅因为伦理问题上的分歧,创始团队就会爆发伤筋动骨的宫斗;而在中国,监管层从大模型上线伊始就要求合规注册。随着AI安全与合规成为企业的必选项,那些懂政策、有经验、能平衡技术创新与合规要求的中年创业者,更容易获得政策支持。
Sam Altman的表现,就是最好的例子。作为OpenAI的CEO,他每年都要参加美国国会听证会,向议员们解释AI的技术边界、安全风险和监管建议。他善于将复杂的技术概念,转化为公众和监管层能理解的叙事,既能推动AI技术发展,又能满足监管要求。
2023年的“董事会风波”中,他快速复职,不仅展现了组织掌控力,更体现了他对监管环境、公众情绪的精准把握。
媒体叙事的转变,更是强化了中年创业者的优势。
Sam Altman和Demis Hassabis的媒体形象,不再是“反叛的创业者”,而是“科学家与思想家的结合体”。媒体报道他们时,更关注他们对AI安全的发声、对社会伦理的思考,关注他们如何负责任地推动技术发展。Demis Hassabis获得诺贝尔化学奖后,媒体重点报道的,不是他的“天才光环”,而是他如何通过跨学科积累,实现AI对科学的突破,以及他对“AI for Science”范式的长远规划。
这种叙事转变,背后是公众的心理需求。AI模型对普通大众而言是“黑盒”,是人们对未知的恐惧,需要通过信赖“成熟人物”来获得心理补偿。
路透社研究院的调查显示,62%的受访者更倾向于信任有专业人士监督的AI内容。媒体聚焦资深领袖,实际上是在向公众传递一种“技术在受控”的信号——而一个40岁、拥有深厚学术背景、谈吐得体的中年人,比一个20岁、穿着帽衫的年轻人,更能提供这种安全感。

中年人主导不意味着排斥年轻人
当然,中年人掌控AI革命,并不意味着年轻人在AI时代没有立足之地,在数十年一遇的巨大蛋糕面前,这两个群体并不是非此即彼的互斥关系,AI时代也同样涌现出了一批优秀的年轻创业者。
月之暗面的杨植麟出生于1992年,2015年以清华计算机系第一名毕业,随后获得卡内基梅隆大学博士学位,师从苹果AI研究负责人Ruslan Salakhutdinov。2023年,31岁的他创立月之暗面(Moonshot AI),推出Kimi智能助手,以“长文本处理”为核心差异化,迅速获得市场认可。2024年,他完成超10亿美元融资,估值达25亿美元,成为国内AI大模型公司单轮最高金额融资的获得者。

张祥雨则是“技术天才”的另一典范。这位1990年出生的研究者,是ResNet残差网络论文的第一作者,论文总引用数超30万次,是深度学习领域最具影响力的研究者之一。2023年,他加入姜大昕的阶跃星辰,担任首席科学家,与姜大昕形成“老中青”技术梯队,为阶跃星辰的多模态技术突破提供了核心支撑。
在AI的实施层,年轻人更是占据了主导地位。
港股上市公司MiniMax的员工中,平均年龄仅29岁,73.8%是研发人员,三分之一有海外背景——这些年轻人,是MiniMax快速迭代产品、实现4年上市的核心力量。智谱AI的员工中,也有大量“90后”“95后”年轻工程师,他们负责技术实现,将张鹏等中年领导者的战略想法,转化为具体的产品和技术。
年轻人是“技术原住民”,他们成长于互联网时代,对新技术、新产品的接受度极高,能快速捕捉行业趋势,敢于尝试颠覆性创新。他们也很少有家庭和财务的双重压力,没有过高的机会成本,能够承受更高的创业风险,能够全身心投入到创业中。他们可以在车库里、宿舍里,用最低的成本尝试新的想法,哪怕失败,也能快速调整、重新出发——这种“无产者”的创新勇气,是他们独特的资源优势。


四个方向与一个期待
AI革命给中年人带来了前所未有的机遇,但这并不意味着,所有人都能抓住这份机遇。
不少中年人,在面对AI浪潮时,会陷入两种极端:要么盲目自信,认为自己的经验足以应对一切,不会被AI所取代;要么过度焦虑,担心自己的经验被新技术淘汰,害怕被年轻人超越。这两种心态,都无法抓住AI时代的机遇。
事实上,中年人要抓住AI革命的机遇,关键不是对抗年龄,而是发挥积累的优势——把自己多年的经验、人脉、资源,与AI技术结合起来,实现厚积薄发。结合一些AI领域先行者的经历,我们总结出四个实战方向供参考。
第一,做领域问题的精准定义者,而非一线执行者。
中年人最大的财富,不是会写代码、会调模型,而是看透了行业中哪些问题是“真正值得解决的”。
龙虾之父Peter Steinberger就是最好的例子。他有过成功的创业经历,其项目被大公司收购,已经财务自由。制作Open Claw(当时还叫Clawdbot)的灵感,来自他旅行时的一个动念:现在的AI大多是一问一答式操作,能不能让它部署在本地电脑,通过WhatsApp等IM软件,直接命令它干活呢?
在推出Open Claw之前,Steinberger已经制作过44个AI项目,结合第一次创业经验,他清晰地知道企业管理者对AI的需求是什么。正是这种时间和经历的积累,助推了开源史上攀升最快项目的诞生。
第二,构建知识图谱护城河,打造不可替代的竞争力。
随着通用大模型的普及,基础模型的能力会逐渐趋同,真正的竞争力,来自将AI与企业内部的非公开、高价值数据相结合。中年人多年积累的行业Know-how、隐性知识,正是构建这种竞争力的核心资源。
梁文锋的DeepSeek,就是靠这种“知识护城河”脱颖而出。他凭借量化投资背景带来的“系统优化”思维,将多年积累的算法经验,融入大模型训练中,专注于“模型架构创新”和“训练效率优化”,在MoE(混合专家模型)、MLA(多头潜在注意力)等技术点形成独特优势,最终以极低的训练成本,实现了接近GPT-4的性能。
中年从业者可以推动自己的组织,建立“语义层”和企业知识图谱,将自己多年积累的隐性知识数字化,然后与AI技术结合,打造出具有行业特色的AI产品。这种将行业经验与算法结合的能力,是刚毕业的AI博士、年轻创业者都难以复制的,也是中年人的核心竞争力。
第三,掌握“敏捷领导力”,做好人机协同的管理者。
AI正在将“固定职位”拆解为“动态任务流”,中年管理者不能再停留在“管理人”的层面,而要转向“管理AI协同的人机系统”。年轻人擅长利用AI工具提高执行效率,中年人则擅长协调资源、统筹全局,两者结合,才能实现效率最大化。
闫俊杰的管理方式,值得中年创业者借鉴。他创立的MiniMax,团队平均年龄仅29岁,他没有采用传统的层级管理,而是打造了扁平化的团队结构,充分发挥年轻人的积极性和创造力。
同时,他利用自己的行业经验,为团队定方向、控风险,将AI工具集成到产品迭代的每一个环节,实现了“年轻团队+中年掌舵”的高效协同,最终仅用4年就完成上市。
中年管理者要学会从“任务指派者”变为“工作流集成商”,将AI集成到决策工作流中,确保AI在决策发生的瞬间,就能提供支持。同时,要学会激励年轻团队,尊重年轻人的创新想法,实现“经验+活力”的双赢。
第四,发挥成熟优势,做好监管沟通者和伦理把关者。
随着AI监管的收紧,信任成为最稀缺的资源。中年人在建立共识、维护透明度、遵循道德规范方面的经验,AI无法模拟,也无法跨越式积累。这种“软实力”,将成为中年创业者在AI时代的另一核心优势。
Dario Amodei就是靠这种“软实力”,赢得了资本和公众的信任。他从OpenAI出走后,始终坚持“有益、诚实、无害”的AI开发理念,通过Constitutional AI技术,实现对模型行为的精细控制,主动应对AI伦理和监管挑战。这种对伦理和合规的坚守,让Anthropic在激烈的竞争中,占据了独特的优势。
中年从业者在AI项目中,要率先建立合规与安全框架,通过建立“人类审查循环”,消除算法偏见,增强组织内外部对AI系统的信任。同时,要关注AI的长期社会影响,确保技术发展符合公司价值观和监管要求,这样才能实现长期可持续发展。
如果说互联网革命像是一场草原上的野火,它迅速焚烧旧有的植被,让新苗得以在废墟上肆意生长。那么AI革命,更像是一场深层的地质运动。它没有烈火烹油的喧嚣,却在缓慢而有力地重塑整个人类社会的底层板块。
当AI真正可用后,执行的成本会被无限降低。但人类多年积累的经验、洞察、人脉和责任,正在成为最稀缺、最不可替代的资源。这一次,机会站在长时间的积累一边。